
If you’ve previously worked on micro-services, you must have hard times in managing a way to connect those services. There are multiple ways to connect micro-services. One of the most used methods is setting up a message broker system (RabbitMQ, Kafka, etc.) between them. REST APIs are not a recommended option due to the overhead of API calls. It takes a few ms just to instantiate a connection, it becomes an overhead when millions of calls have to be sent. The most fantastic way to connect micro-services is, gRPC.
We’ll go through multiple aspects of it to prove why gRPC is the most recommended way.
What is gRPC?
From grpc.io:
gRPC is a modern open source high performance Remote Procedure Call (RPC) framework that can run in any environment. It can efficiently connect services in and across data centers with pluggable support for load balancing, tracing, health checking and authentication.
The definition is pretty clear that gRPC uses the RPC framework.
RPC is a protocol that allows one program to request services from another program running on a different host on the network. The program doesn’t need to know anything about the network details.
Sounds much like REST APIs, isn’t it?
Yes, it mostly works like REST APIs except it has a few standards to follow. One of the most important standards is Interface definition language (IDL) which is a common language both programs have to use to talk to each other. By default, gRPC uses protocol buffer (a.k.a. protobuf) as IDL.
The recommendation is not to use gRPC in public-facing applications (like frontend-backend connection), due to the structure of request-response in both client as well as server applications. It will reveal the structure of the IDL which could become a security concern. gRPC uses HTTP/2 for the RPC calls.
To dig more, let’s first discuss the problem we faced.
Problem Statement
Sendinblue receives thousands of requests per second from clients around the globe. There are more than 100 microservices in the system to work on those messages and we needed something which could connect the needed services without giving overhead or data loss issues. Initially, we were highly reliant on RabbitMQ to connect the micro-services but considering the message rate and high publish at some instances, we, at times, faced multiple issues from RabbitMQ. One of them was flow-control.
The definition of Flow-control as per From RabbitMQ docs:
RabbitMQ will reduce the speed of connections which are publishing too quickly for queues to keep up. It requires no configuration.
We need to manage highly available RabbitMQ clusters, as even 100ms of downtime would add a lag in the whole system.
Proposed solution
We needed something that:
- could process messages at the same or higher rate compared to RabbitMQ
- gives no overhead in message forwarding
- this doesn’t requires dedicated host for managing
- would not overwhelm the network in forwarding the messages
- would be less prone to errors
So, we required self managed APIs, without the need of host. Choosing REST would definitely overwhelm the network at such a high rate. Also, we’d be more prone to losing data on any type of internal error.
At this point, we checked out gRPC which perfectly suited our use case.
Following are a few of the points why we considered gRPC:
- It’s designed to use in connecting micro-services
- It’s highly available with an in-built retry mechanism for failed requests
- It uses HTTP/2 which uses multiplexing to send multiple requests over a single TCP connection
- It doesn’t require any host to setup/manage
- As HTTP/2 compresses headers, gRPC won’t overwhelm the network and thus would have a lighter network footprint per message
- … and many more
Considering it might solve our purpose, as a result we gave it a try, and it turns out to be astonishing.
As a matter of fact, gRPC was able to handle all the requests at the same rate as RabbitMQ. In addition latency was nearly the same. Another key point was we didn’t have to manage a dedicated host just to connect the services.
Before going into the architecture and implementation, let’s look into some data that clearly shows the effectiveness of gRPC.
gRPC implementation results
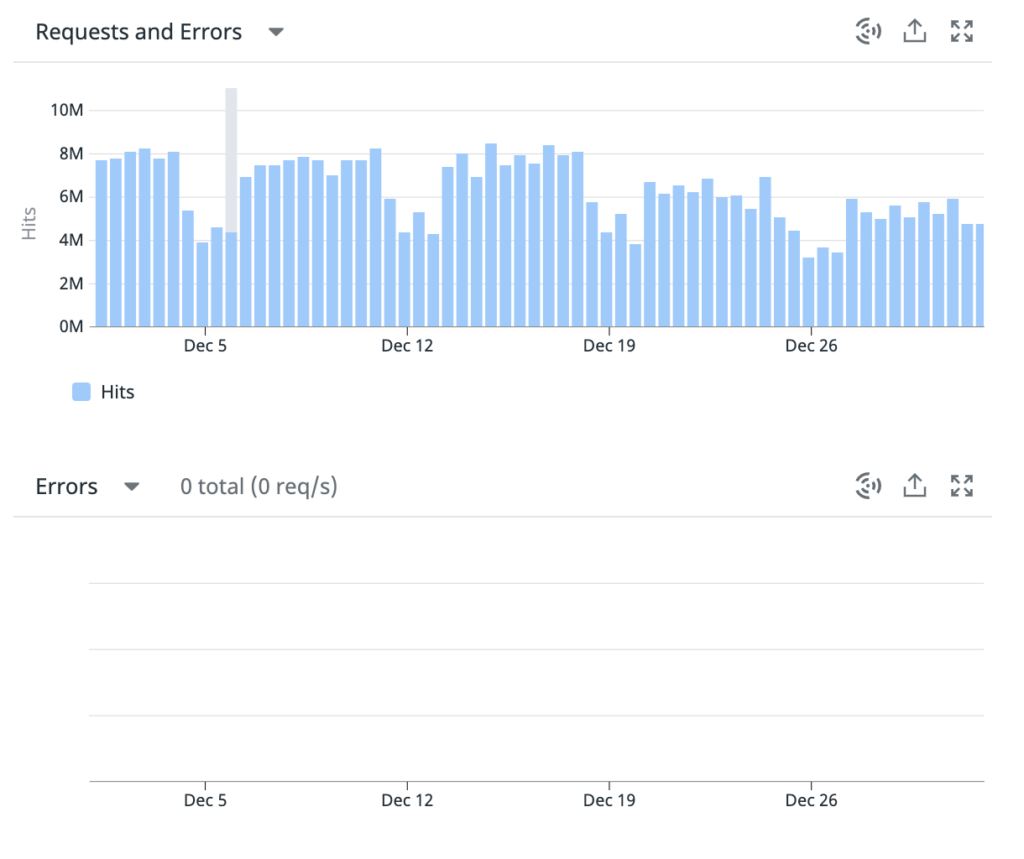
The data is of one of the services that receive 7 million requests/day on average. During 1 month, the gRPC consumed ~387 million requests with 0 error rate.
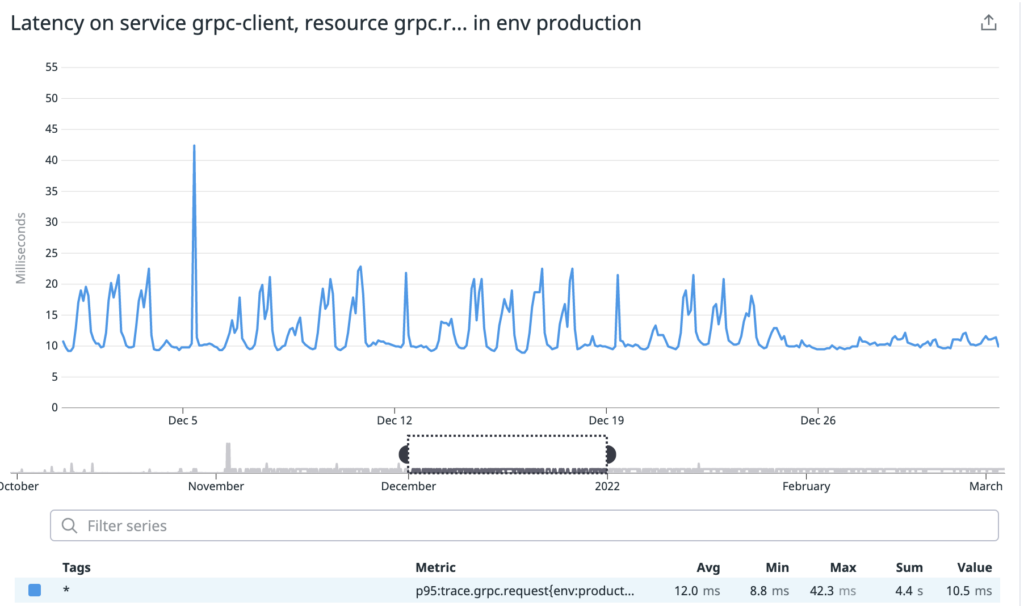
The picture shown above is p95 latency graph. The latency has spikes at some moments but the consumption rate by the service was always amazing with 0% error. As we can see, there are no errors we can define gRPC call as fire & forget type. The latency seems flattening after the release.
In our case, gRPC with fire & forget call was a big improvement over RMQ model.
Now let’s dig into the architecture and write some code to implement gRPC in the system.
Client-Server Architecture with gRPC
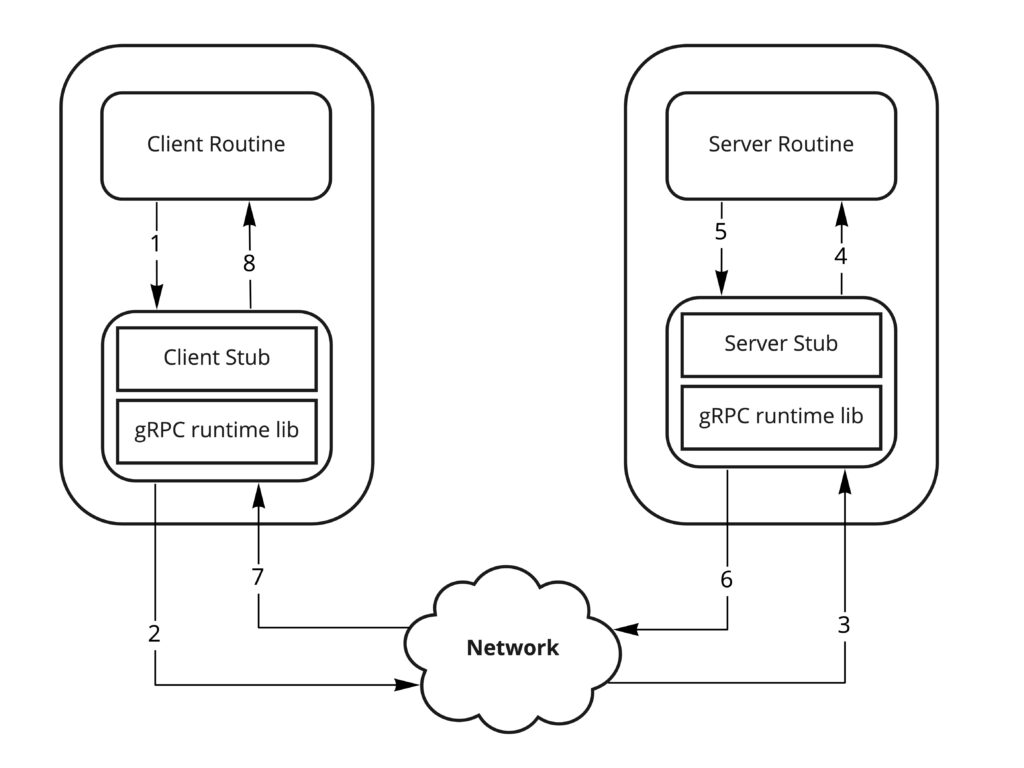
Please refer above diagram for gRPC architecture. There are 8 steps illustrating above diagram:
- Client application prepares and send data for serialization using client stub
- gRPC forwarded encoded data to network
- The server receives the data and deserializes it by server stub
- Server application processed received data
- The server prepares the response and serializes it by server stub
- gRPC forwarded encoded response to network
- The client receives the response and deserializes it by client stub
- Client application processes response
Here the stubs are IDL and default IDL in gRPC is protobuf.
IDL: Interface definition language
It is a common language for client & server applications to process request-response.
Advantages of gRPC
- It uses HTTP/2 under the covers which gives it the power and benefits of HTTP/2 protocol like:
- Request-response multiplexing, which allows the client & server to break down the message into independent frames, interleave them and reassemble it on the other end
- One connection per origin: HTTP/2 doesn’t need multiple TCP connections to multiplex streams in parallel. Only one connection per origin is required in such cases
- Header compression: In HTTP/1 header transfer becomes an overhead as 500-800 bytes of data has to be transferred on each HTTP call. HTTP/2 compresses the header metadata using the HPACK compression in which both client & server is required to maintain and update an indexed list of previously seen header fields which is used as a reference to encode previously transmitted values etc.
- It has an in-built load balancer to balance traffic among multiple servers
- Protobuf, a lightweight message format used for serializing gRPC messages.
- gRPC messages are always smaller than equivalent JSON messages.
- It is designed for low latency and high throughput communication which makes it perfect to use
Implementation
gRPC client and server applications are independent of programming languages i.e. both can be written independently in any of the supported languages. To demonstrate, we will be using Node.js for both. For the sake of simplicity, the client and server will be implemented in the same project.
We will be creating an endpoint to send employee information containing name, phone numbers (array), occupation & is_working_professional fields from the client to the server application.
The sample project can be downloaded from gRPC example application Git repository.
Steps:
- Initiate the Node.js project and install required libraries @grpc/grpc-js & @grpc/proto-loader.
- Create a protobuf file (reference guide) that contains the request and response format.
syntax = "proto3";
service EmployeeInfoService {
rpc EmployeeInfo(EmployeeInfoRequest)
returns (EmployeeInfoResponse) {}
}
message EmployeeInfoRequest {
required int64 id = 1;
required string name = 2;
repeated string phone_numbers = 3;
optional string occupation = 4;
bool is_working_professional = 5;
}
message EmployeeInfoResponse {
int64 response_code = 1;
string message = 2;
optional string err = 3;
}Explanation:
We created a message.proto file above, a protobuf file that has the RPC method, its input request type, and response type. In the beginning, we need to mention which proto version syntax we are going to use. There are multiple proto syntaxes available, we are going to use proto3 one. After that, we defined the EmployeeInfo service which has an RPC method defined that will take EmployeeInfoRequest as input and will return EmployeeInfoResponse. Finally, we have defined the structures (stubs) of EmployeeInfoRequest and EmployeeInfoResponse.
- Create the server application that will define the required method exposed in
message.proto
const protoLoader = require("@grpc/proto-loader");
const grpc = require('@grpc/grpc-js');
const MESSAGE_PROTO_PATH = __dirname + "/message.proto";
const packageDefinition = protoLoader.loadSync(MESSAGE_PROTO_PATH, {
keepCase: true,
longs: String,
enums: String,
arrays: true
});
const EmpService = grpc.loadPackageDefinition(packageDefinition).EmployeeInfoService;
function EmployeeInfo(call, callback) {
console.log(`Recieved input ${JSON.stringify(call.request)}`);
callback(null, { response_code: grpc.status.OK, message: "Successfully sent message using gRPC" });
}
function getServer() {
const server = new grpc.Server();
server.addService(EmpService.service, {
employeeInfo: EmployeeInfo
});
return server;
}
const routeServer = getServer();
routeServer.bindAsync('localhost:9000', grpc.ServerCredentials.createInsecure(), () => {
console.log("Server starting...");
routeServer.start();
});Explanation:
- Initially, we imported the required libraries and the proto file (lines 1-4).
- Then uploaded Proto files with different configurations (lines 6-11).
- Then we imported the service defined in the proto file (line 13).
- We defined a function EmployeeInfo for that purpose (line 15-18).
- After that, we have initiated the gRPC server instance and mapped the required functions (lines 20-26).
- gRPC server runs on load of all configurations(line 27-31).
- gRPC server started on port 9000, you can use any available port.
- Define client application that will be used to call the server application with required input data
const protoLoader = require('@grpc/proto-loader')
const grpc = require('@grpc/grpc-js')
const MESSAGE_PROTO = `${__dirname}/message.proto`
const packageDefinition = protoLoader.loadSync(MESSAGE_PROTO, {
keepCase: true,
longs: String,
enums: String,
arrays: true
})
const EmployeeInfoService = grpc.loadPackageDefinition(packageDefinition).EmployeeInfoService
const customConfig = {}
const grpcClient = new EmployeeInfoService(
"localhost:9000",
grpc.credentials.createInsecure(),
customConfig
)
const gRPCReq = {
id: 1,
name: "John Doe",
phone_numbers: [12345678, 98765432],
occupation: "Data Analyst",
is_working_professional: true
}
grpcClient.employeeInfo(gRPCReq, (err, response) => {
if (err) {
console.log(`gRPC Error: ${err}`);
}
console.log(`gRPC Response: ${JSON.stringify(response)}`);
})Explanation:
Line 1-13 is the same as we defined in server.js above. On lines 15-20, we defined the gRPC client that connects to the server. Subsequently, we created input request data to be sent to server (lines 22-28). The variable name and type have to be the same as it is defined in message.proto file. Then we call the gRPC function exposed in message.proto (lines 30-35) that sends all the defined data to the server and logs the response/error returned from the server.
Conclusion
This is all we need to implement gRPC client and server applications.
Though the learning curve of gRPC is higher than REST, potential benefits and performance justify it. Sendinblue achieves an incredible performance improvement through APIs created by gRPC. Introduction of fire & forget gRPC call helps in reducing response time of the service to a few microseconds.