Introduction
At Sendinblue, we send more than 100 million emails per day and each mail is personalised with respect to the recipient. We use the Redis cluster extensively to store these emails and forward them to the ESPs (recipient inboxes). We are talking about terabytes of data flowing through our system each day.
The Challenge
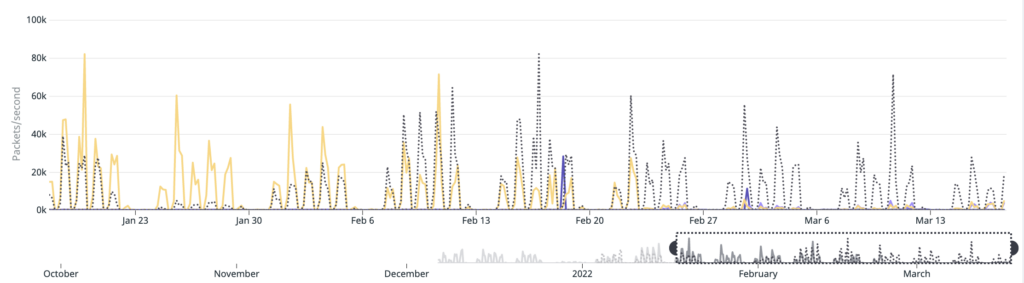
Our Redis cluster is more than capable of handling millions of emails per day but we started facing issues due to high network throughput. The network link connecting our DC(Data Center) rooms started getting saturated during peak traffic hours and as a result, we started suffering packet loss on the network. This was not just impacting our Redis cluster and MTA(Mail Transfer Agent) but also our other apps hosted in the same DC rooms.
Unfortunately, we didn’t have the option to switch to a different rack/room in the DC. So the issue needs to be solved on the software side.
Compression
The solution is very easy we just have to reduce the data we transfer over the network and to do so we have to reduce the data we store in the Redis cluster.
But, we are already compressing our data using snappy and it’s not enough. We need better compression, but how?
What’s Delta Compression?
Delta generally refers to the difference between any two sources, i.e. a source and a target. The algorithms that work on delta compression(sometimes also referred to as delta encoding ) generally takes the source and target as inputs and provide the delta as output. This delta can then be used to “patch” with the original source to get the target.
Each client who sends out a campaign does so with minimal or no changes in the template for each of his contact and we add the personalisation for it. So, in short, for each marketing campaign, the base template is the same for all recipients.
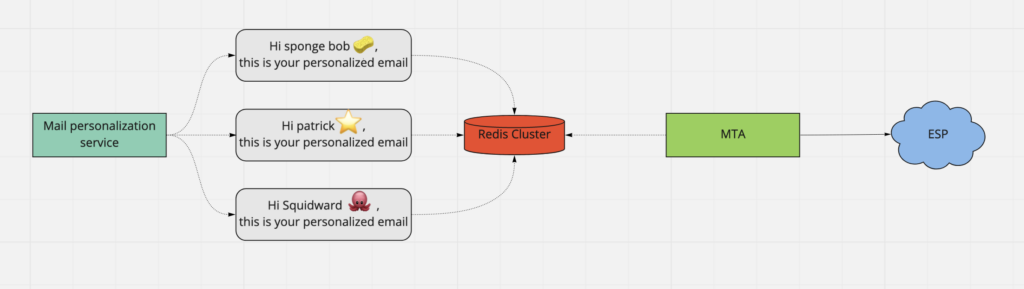
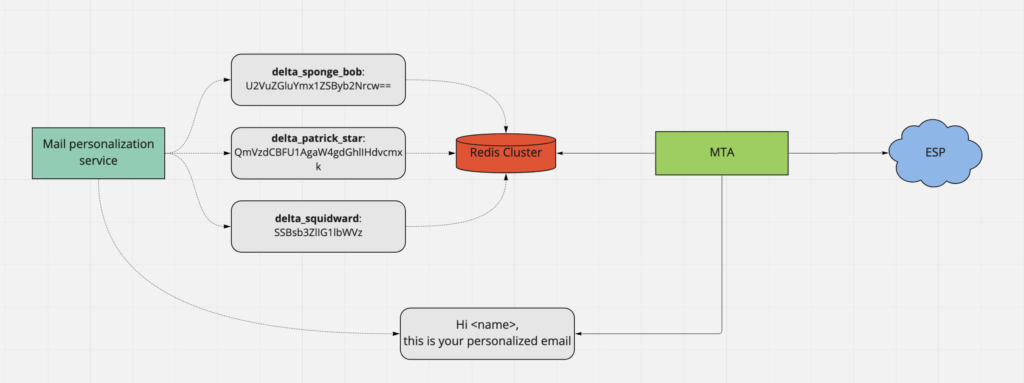
We can leverage this to our advantage by generating and storing only the delta in the Redis cluster and reconstructing the personalized final mail using the delta and base template(as the source which is stored in a No-SQL database) for each recipient.
How did we go about it?
We, at Sendinblue engineering, did some initial PoCs to check the performance of some of the delta compression libraries that are available in Golang, namely, godelta, bsdiff and xdelta. Go-delta and bs-diff were the finalists with the following benchmarking:
| Tool | Source Input Size(Kb) | Target Input Size(Kb) | Delta File Created(Kb) | Compression Ratio(%) | Space Saving(%) | Memory Usage | Run Time(time take by script) |
|---|---|---|---|---|---|---|---|
| Go-Delta | 97.6 | 140.2 | 59.5 | 2.35 | 57.56 | 57228 allocs/op | 2.264s |
| BSDiff | 97.6 | 140.2 | 49.4 | 2.84 | 64.76 | 229 allocs/op | 2.501s |
As from the above benchmarks, bsdiff was a clear winner for us! So we went ahead and integrated the delta compression using bsdiff library in our applications.
Happy Ending can’t be too soon, right?
As we went live with bs-diff, we started getting complaints from some of our customers that they are seeing some random characters in the emails. It could only mean two things – either there is an issue while creating the delta or while applying the patch.
The library produced inconsistent results and we were not able to replicate it at our end even with thorough testing. It all looked great!
Then, we thought of giving go-delta another try!
But now we faced another issue – the producer that was creating the delta is built using Golang whereas the consumer which was going to apply the patch was written in NodeJS.
It became a major challenge to find any updated and well maintained npm package for go-delta. We tried using ffi-napi npm module, but it was adding significant latency to the overall processing. Hence, we implemented a sidecar container approach for patching the delta in Golang at our consumer end, but that’s not the end of the story we again faced an interesting issue and this time it was related to memory and CPU consumption.
Custom implementation of Delta compression:
Once sidecar was ready and we were successfully patching the delta in order to generate final message, we found that the CPU and memory usage went high exponentially! Upon investigation, we found out there were a few improvements needed in the library itself:
- Compression algo: By default
go-deltauses zlib compression which is less efficient and takes more memory compared to snappy so we made custom implementation with snappy compression and let the caller (Producer) decide which algorithm it wants to use. We kept the option to change between the algorithms so that we can switch between different algorithms and find out the best performing one. In our case we are using snappy as default compression algorithm now. - BuffPool implementation:
go-deltauses native string buffer which copies the whole string in memory and do the manipulation. We implemented custom bufpool which creates a pool of buffer and save memory usage. - Temp Buffer: Another issue we found with the library is it uses by default 32MB temp buffer which loads in memory with every request, and in Sendinblue we allow maximum 5MB email body for marketing campaigns so we reduced the temp buffer to 5MB, it also helped to save memory usage as well.
- Struct Reordering: We also reordered the struct and handle memory padding issue, which helped to reduce the memory usage.
Final Results
Soon after we went live again, we could identify that there was a race condition while generating the delta which led to the issue, thanks to the exhaustive error-handling done in the library! We handled the issue and it worked like a charm.
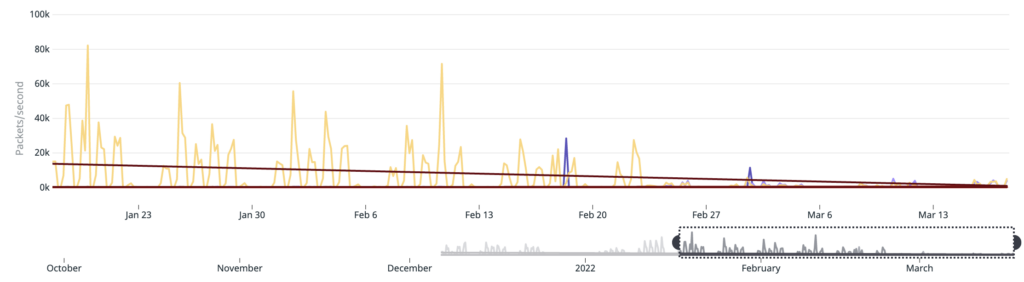
We did some additional changes for improving the compression of the delta being generated and were able to reduce the packet loss by a factor of 20x.