
Segmentation to target the right audience is very crucial for a business entity. It ensures the right content for the customer and helps increase the conversion rate and hence the business. Furthermore, it makes sure that irrelevant communication will not disturb valuable customers.
How are we helping clients target the right audience?
At Sendinblue, we provide support for multiple attributions of a contact (or audience). A client can add attributes of different data types mentioned below:
- Text
- Date
- Number
- Category
- Boolean
To store these attributions, we use a NoSQL database i.e MongoDB. This led to a problem statement where we can have different attributes available for different clients.
Hence, we needed something which can dynamically generate database queries as per the available attributes of a client.
What about actions performed by contacts?
At Sendinblue, we keep a record of multiple actions performed by a contact: opening an email, clicking a link, visiting a website page (via tracker), placing an order (via plugins), etc.
All these actions performed by contact are quite relevant to target the right audience.
We keep a record of these events based on their event family like email-related events belonging to a family named email. Similarly, website-related events belong to a family-named website and hence these events are distributed among multiple tables per event family.
To perform highly optimized and performant queries for actions or events generated for contact, we keep them in Clickhouse. More on Clickhouse usage later.
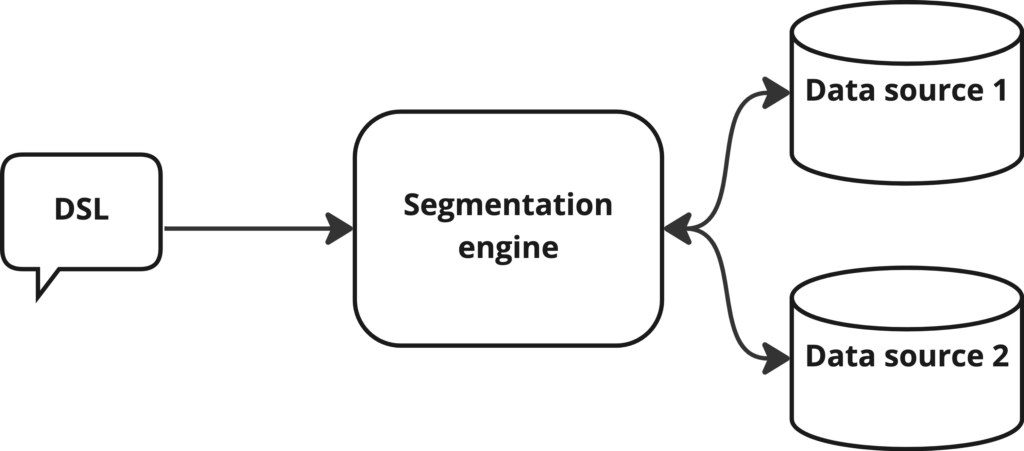
In-house segmentation engine
We have developed an in-house segmentation engine to fulfill the vast use cases to support segmentation.
While developing it we ensured to keep it optimized and performant per data source (more on this later).
As shared earlier, contacts can have attributes that are very specific for a particular client. The same is true for events data per event family which leads to a need for a language that can communicate with the engine to target expected contacts (or audience).
DSL (Not Digital subscriber line, ?)
DSL is Domain Specific Language that we defined to communicate with the engine.
As shared above, the contact attribution is not pre-defined and actions data are specific to the event family.
Hence, it becomes evident to define a language schema that can support dynamic contact attributions and any new family that will be introduced into the system.
We chose data type to be the basic entity of DSL so that any contact attribute or event column (data) can be queried by passing their name in the DSL.
Thus, the outcome looks like this:

Based on data type, we provide different operations that can be performed. For example, for text type attributes we can perform equal, contain, start with, or end with operations.
We further provide these options in the DSL itself like below:

These two steps above make the DSL self-explanatory to define criteria for any data or attributes defined by clients.
For example, if a client creates a text type attribute named ‘LOCATION’ and wants to define criteria for contacts who belong to Paris. The corresponding DSL would be like the below:
{
"attribute": {
"name": "LOCATION",
"text": {
case_sensitive: true,
equal: "Paris"
}
}
}The segmentation engine will be able to translate this DSL to the corresponding MongoDB query.
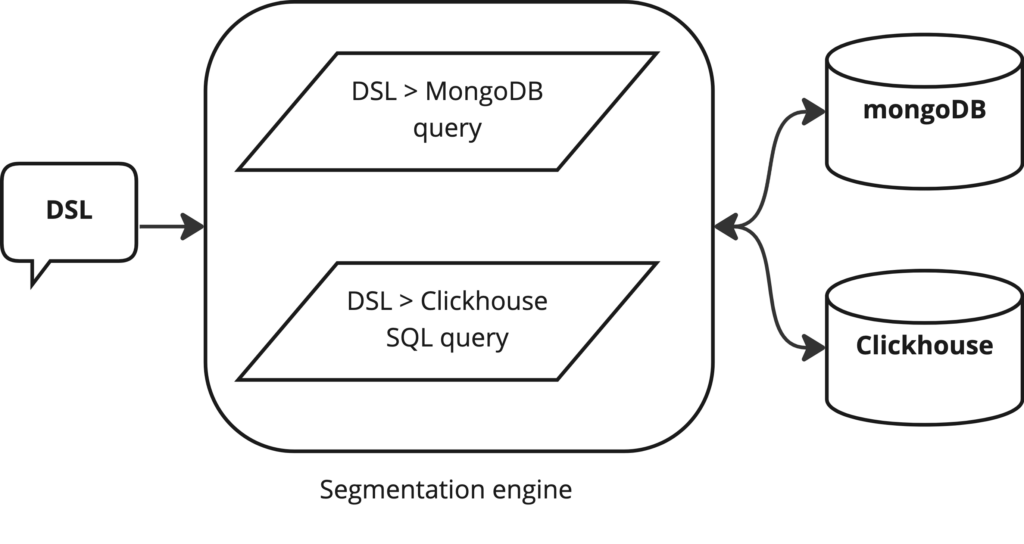
Multiple data sources support in segmentation engine
As stated previously, we keep events data on Clickhouse, it invokes provision for the data source in the DSL itself. Since different data sources support different data types, we do need to keep the data source information at the top level in the DSL schema.
Data source > Data column > Data type > Values
To describe this pipeline for our previous example, it will become something like below:
MongoDB > Name (LOCATION) > Text > Value (Paris)
NOTE: This strategy helped us to provide the flexibility to extend our system for any new data source we might introduce in the future.
Optimization per data source
Clickhouse
Clickhouse is designed to process billions of rows and tens of gigabytes of data per server per second. It is doing great as per our use case and needs.
No additional optimization is to be done other than having basic performance checks in a place like to have indexes, order keys, etc.
You can find more details about Clickhouse index design here.
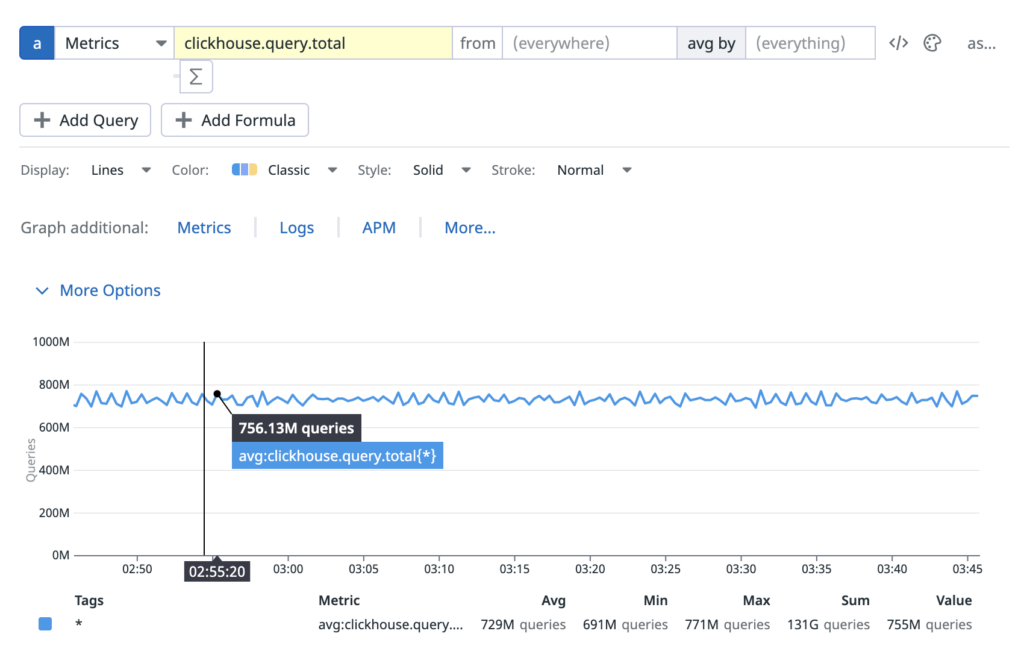
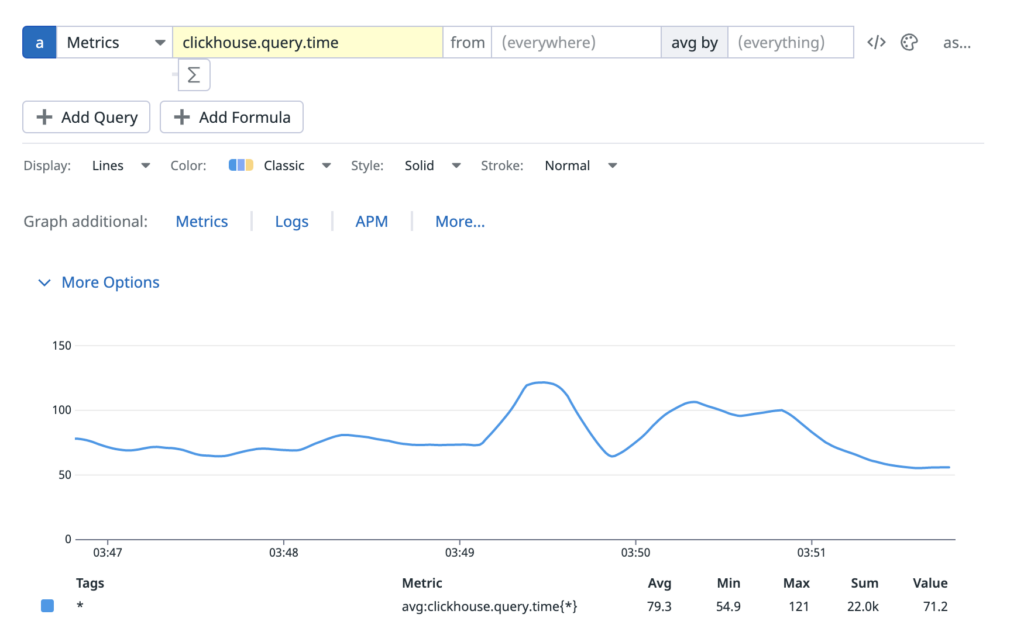
Clickhouse is serving ~729 Million queries per hour with a query time of approximately ~100ms.
Challenge with MongoDB
As per our use case, we can’t create indexes for each and every attribute which is being created by our client to optimize our MongoDB query.
Since we provide support for each attribute, the DSL to MongoDB query generator would generate non-performant queries which could be a bottleneck for segmentation engine performance.
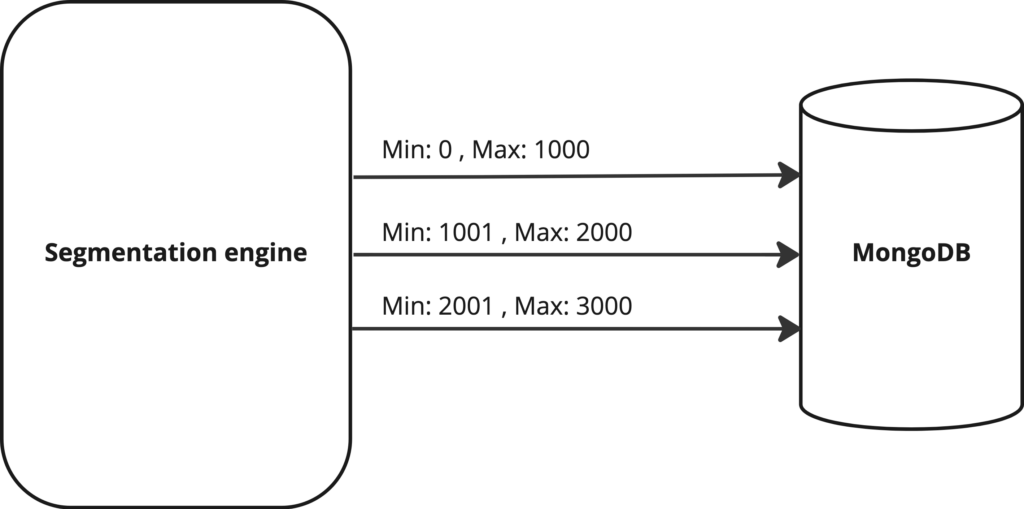
We also decided to run parallel queries on MongoDB in batches of data stored, to get the results faster than waiting for one single query to return the required data.
To make use of the proper index and create appropriate data batches to query upon, we choose the existing unique key based on the cursor hint.
We create multiple batches called ‘buckets’ based on a unique key. Each bucket has a min and max value for the unique key and based on these min and max values of the bucket.
We made the parallel call to MongoDB to parallel process our query and hence get more data in less time. 🙂
db.collection.find({LOCATION: "Paris", <unique-key> : {$lt : <max-value>, $gte : <min-value>}}).hint(<unique-key> : 1);
We do union operation on the data we receive from multiple batches and then be able to get all contacts matching the segment criteria.
Challenge with Clickhouse
We had a case to support where we do need to identify if a particular contact is matching the defined segment criteria or not.
As explained here, Clickhouse recommends limiting the number of queries per second for better throughput, and in this above case, the scale of the queries would not be as performant.
DSL comes to the rescue, and we introduced a new data source (BigTable) to store events along with Clickhouse which is performant enough to scale the use case discussed above.
The extension in DSL allows us to target BigTable instead of Clickhouse for this specific use case.
Combining criteria of multiple data sources
To target the right audience, we can’t just rely on attribution and actions performed by contacts separately. We need a way to combine the criteria of both sources.
The extension in DSL solves this issue, We introduce UNION and INTERSECT set operations at the top level to allow the extension in DSL to support multiple criteria of multiple data sources.
The pipeline would typically look like this:
SET OPERATION > [{Data source > Data column > Data type > Values}]
Example with multiple data sources:
UNION > [{MongoDb > Name > Text > Value}, {Event (clickhouse) > Name > Text > Value}]
The flexibility in DSL schema allows us to add as many criteria per data source and also provides scope for extension to introduce new data sources in the future.
We developed a segmentation engine in Go and highly use slices to store the contacts matching the segment criteria. Each slice consists of contact ids of the respective criteria.
To support the UNION and INTERSECTION operations, we process the slices.
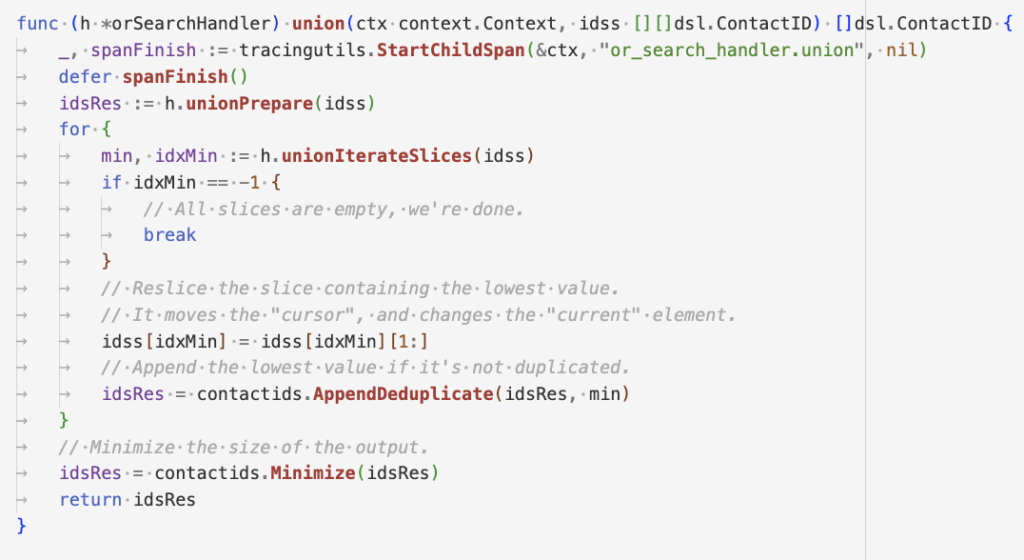
UNION
Slice 1: {MongoDb > Name > Text > Value}
Slice 2: {Event (clickhouse) > Name > Text > Value}
UNION: {Slice 1} ∪ {Slice 2}While processing UNION, we follow below steps:
- Sort the slices in ASC order as each slice consists of uint i.e. contact id.
- Create an empty slice with the capacity to hold all the contact ids.
- Discard empty slices.
- Find the lowest value of each slice.
- Re-slice the slice containing the lowest value to move it to the next element and append the contact id if it’s not duplicated.
- Repeat step 4 until traverse all the ids of all slices.
- Minimize the capacity of the slice. (To reserve memory)
This is an example code snippet:
INTERSECTION
Slice 1: {MongoDb > Name > Text > Value}
Slice 2: {Event (clickhouse) > Name > Text > Value}
INTERSECTION: {Slice 1} ∩ {Slice 2}While processing INTERSECTION, we follow below steps:
- Sort the slices in ASC order as each slice consists of uint i.e. contact id.
- Discard empty slices.
- Create an empty slice with the capacity to hold all the contact ids.
- Find the lowest value of each slice and also check if the lowest value of each slice is the same or not.
- If the lowest value of each slice is not equal, we do re-slice the slice containing the lowest value to the next element and repeat from step 4.
- Append the contact id if the lowest value is not equal.
- Re-slice all slices to the next element.
- Repeat step 4 until traverse all the ids of all slices.
- Minimize the capacity of the slice. (To reserve memory)
This is an example code snippet:

Performance of segmentation engine
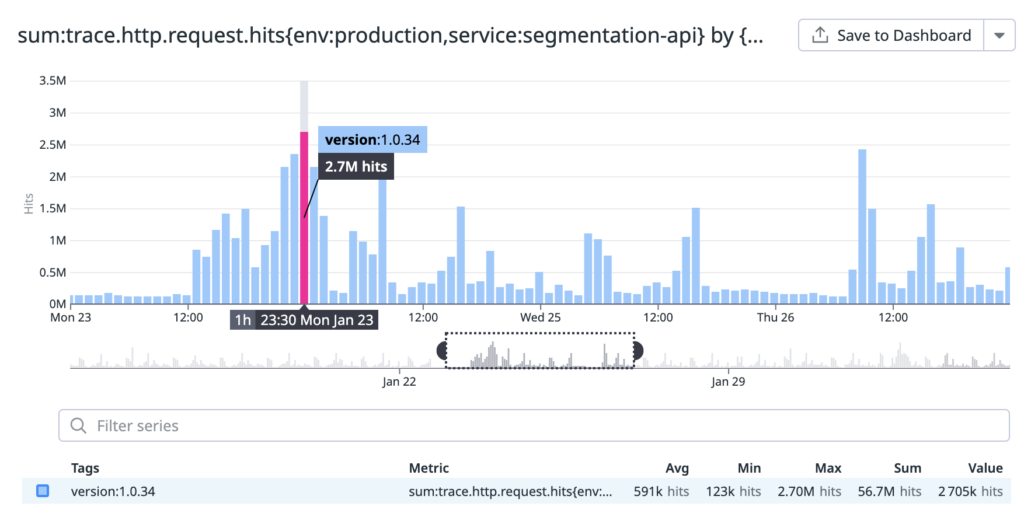
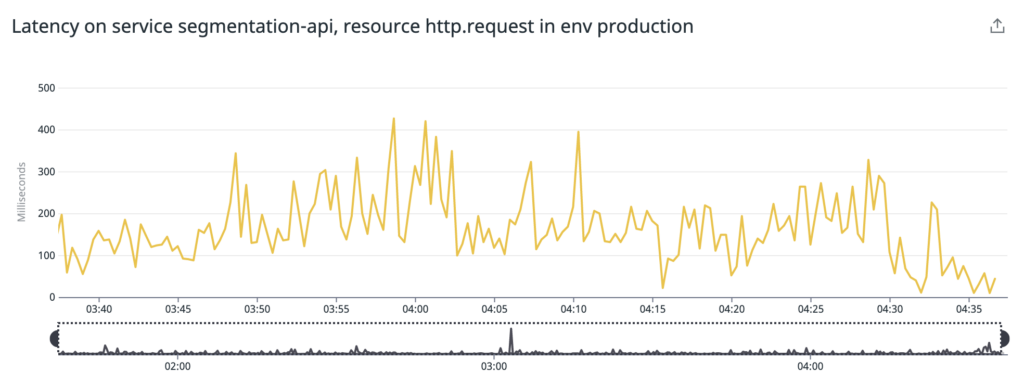
The segmentation engine is currently serving max 2.7 Million hits per hour and keeps the P95 latency below 400ms.
Hits per hour:
P95 Latency:
Happy learning ?