
Summary
The corporate domain name used to host the Brevo platform (brevo.com) expired on September 11th, 2023. As usual, during a domain expiration, the domain was disabled and redirected to an empty page unrelated to Brevo’s activity, resulting in progressive service degradation impacting our customers around the world.
The domain was renewed 6 hours after its expiration, and services were restored progressively thereafter.
Root causes
We have identified three main isolated causes, which, when linked together, led to the incident.
Registrar account misconfiguration
Earlier this year, we acquired the domain brevo.com as part of our rebranding from Sendinblue to Brevo. During the acquisition, we were legally required to keep the same registrar as the previous domain owner, which was not our usual one. We created a new account on this registrar and transferred domain ownership to it. As usual, we enabled the necessary settings including domain transfer lock, automatic renewal, and payment method.
Broken notifications
During the summer, we disabled the email address configured to receive domain name expiration notifications from this registrar without realizing its importance.
Payment method failure
The payment method used to renew this domain expired before the domain renewal.
Missing monitoring
We monitor the status of all our domain names automatically through an external service. However, brevo.com was not included in this list because the new registrar hasn’t been included to our domain auto-discovery pipeline.
Trigger
While the root causes created a situation propitious to create an outage, it was missing an event to trigger it. This event happened on September 11th, 2023 when the domain expired.
Resolution
We attempted to renew the domain as soon as we noticed its expiration. A process that usually only takes a dozen minutes. Unfortunately, we met some unexpected issues, which made things worse:
- The payment method update triggered their anti-fraud process and flagged our account for manual review
- Despite our attempts to resolve the issue through their 24/7 support team, they were unable to validate our account or bypass the manual process, which was handled by their compliance team, operating only from the US West Coast (PDT) business hours
As the situation was at a complete standstill, we considered the following actions in order to restore our domain as quickly as possible:
- Transfer our domain to another registrar: Although technically possible, this operation would potentially take several days to complete.
- We deployed our platform on a backup domain to recover the service. We initiated the change without knowing its duration because we had not configured our configuration management to operate in this manner. Fortunately, the domain came back before we finished this step.
- Escalate the issue to the registrar executive team we successfully reached someone from the company who escalated internally.
As soon as we escalated the issue internally, support sent us optimistic messages, confirming that they had validated the account and initiated the renewal process for the domain.
A few minutes later, we effectively renewed the domain. Our service became progressively available in the following hours, depending on DNS propagation.
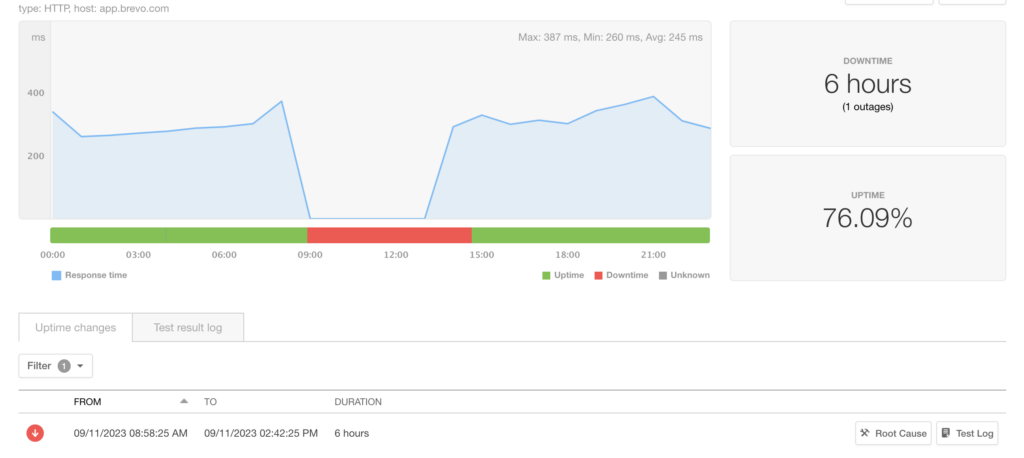
We lost brevo.com the domain for 5 hours and 53 minutes.
The duration of the incident for our customers is complex to calculate, as it depends on their DNS configuration.
Our monitoring probes reported an approximately 6h outage.
Impacts
During the outage, the whole platform continued to operate normally. In the background, already scheduled campaigns were processed, emails were still being delivered, and redirection links were working.
The main disruptions were in accessing our websites, our public API, and our SMTP Relay under the brevo.com domain. Applications that continued to use our API and SMTP Relay under the domain sendinblue.com were not impacted.
Lesson learned
The incident resulted from a combination of multiple factors and revealed some mandatory actions we will take in the coming days or weeks in order to improve our stability and our communication.
Status page isolation
During the incident, our incident public communication tool – the status page – was not available. We understand the critical role this component plays during these events, and will take steps to improve its isolation from our platform, at all layers:
- Domain Name: We will host the status page on a dedicated domain name
- DNS: We will host the DNS for the domain name zone with a different provider than the one we use on our platform.
- Hosting: we will make sure our status page provider does not use the same hosting stack as ours
Domain name registrar uniformization
It does not make sense to keep multiple registrars unless there is no other solution for specific top-level domains. We already manually reviewed all our domain name expirations, their auto-renewal, payment method, notification methods, and monitoring. We didn’t identify any anomaly.
However, we found a lack of documentation and centralization. Our teams were managing domain subscriptions autonomously, resulting in duplicate registrar accounts, or multiple registrars’ usage. We already created a new process to order and manage domain names by a single team, and are now working to migrate all already existing domain names under this team’s ownership. This process includes better notification management and mandatory domain name monitoring from an external service.
Configure a failover domain for critical services
Critical services, such as our public API or SMTP Relay, were not accessible under the brevo.com domain. Although we informed our customers early to switch to the sendinblue.com domain, we understand the inconvenience caused by these changes.
To avoid such issues in the future, we will work on improving those service resiliency, by deploying a second path to reach them.
Timeline (UTC Time)
- 10th September:
brevo.comdomain was about to expire and a notification was sent to an expired email alias - 11th September:
- 6:50 am: Domain name servers updated – the start of the outage, appearing slowly thanks to the DNS propagation
- 6:58 am: First alerts triggered to the infrastructure team from external monitoring
- 7:05 am: Initial investigation started
- 7:40 am: War room created due to the magnitude of the issue
- 8:35 am: Root cause identified
- 8:40 am: Our registrar anti-fraud process locked our account due to suspicious activity (new payment method + contact details update), preventing us from renewing the domain
- 8:50 am: Reached out support to unlock the account
- 9:30 am: We initiated various escalations to the registrar’s executive management.
- 12:41 pm: Account unlocked and domain retrieved. NameServers updated back to our Authoritative DNS provider. This marks the end of the domain misconfiguration
- 12:42 pm: Alerts progressively start to resolve
- 12:50 pm: Google and CloudFlare DNS Resolvers cache flushed to speed up resolution for end customers
Background
Domain name management
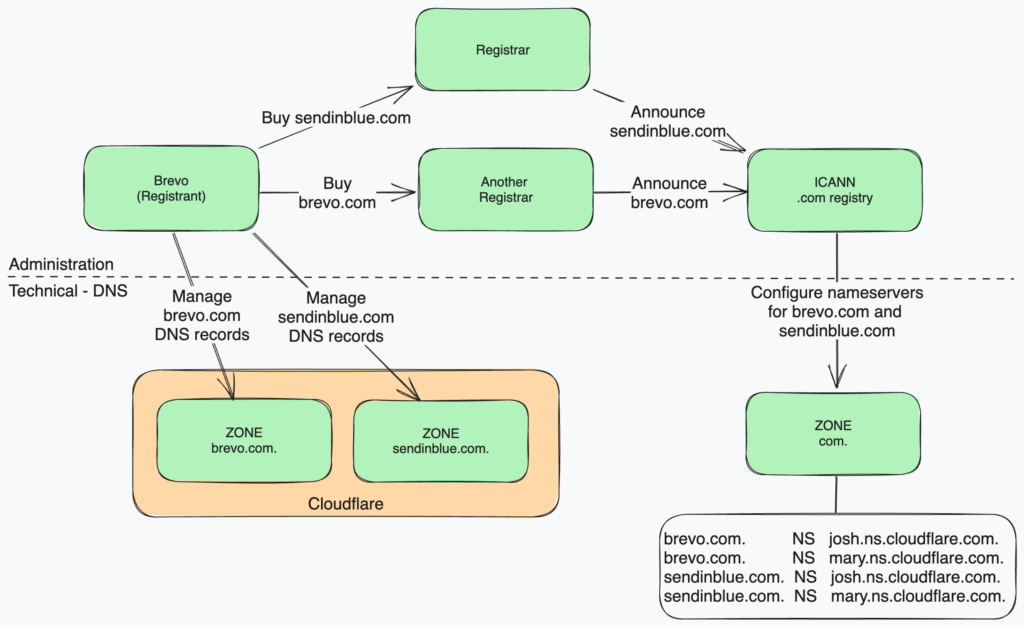
Domain names, such as brevo.com, are strings used to identify companies, corporations, government entities, and even individuals on the internet. Companies called “Registrars” borrow these names for a fixed period of time and announce the domains on a centralized system based on the DNS protocol. Registrars act as a bridge between Registries – the organizations owning Top Level Domain (such as .com, .tech, .io…) and companies or individuals looking for a domain name (called “Registrants”).
Registrars also offer a DNS service along with domain registration, in order to host the DNS configuration of the domain names they sell. Registrants can either decide to host their DNS zone on Registrar name servers, or on custom name servers of their choice. We, at Brevo, are using custom name servers for our production domain names.
That being said, taking an alternate registrar, like we did for brevo.com, is technically completely transparent for us and our customers, as they are not implied on the DNS resolution path.
DNS Resolution
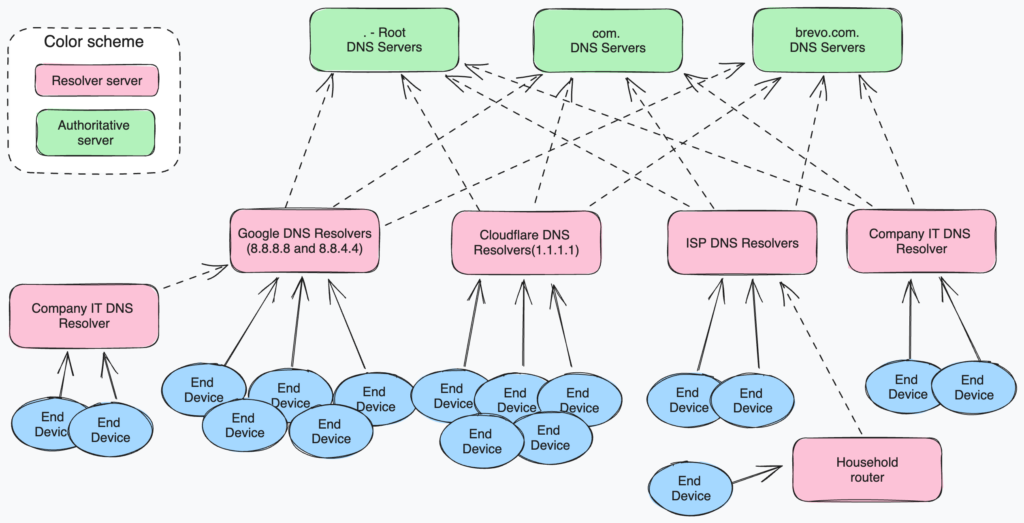
One of the main purposes of the DNS protocol is to convert a DNS name such as brevo.com, app.brevo.com, or status.brevo.com to an IP address.
To achieve this, we store the mapping between DNS names and IP addresses in what we call “DNS Zones,” and we distribute these zones across different DNS servers in a tree structure. We refer to the DNS server configured to serve a zone as the “Authoritative” server.
To optimize the response time and reduce the load on authoritative servers, you can use another type of DNS server between authoritative servers and end devices (such as computers, servers, and smartphones). These servers, known as “DNS Resolvers,” maintain an internal cache of the records they have previously requested. If a client requests an unknown DNS record, the Resolver will make a request to the Authoritative server and store the answer in its own cache. The cache duration is variable and depends on the DNS Record configuration on the Authoritative DNS Server. It may vary from a few seconds to many weeks.
F.A.Q.
The incident continued even after the announcement of the service restoration. Why?
This is due to the nature of the DNS protocol, which relies on multiple caching layers. The process called DNS Propagation consists of progressively refreshing caching layers of data.
After restoring the domain, we initiated a cache flush on two of the major public DNS resolvers: Google (8.8.8.8 and 8.8.4.4) and Cloudflare (1.1.1.1). Other DNS Resolvers don’t offer this possibility, so we were not able to force the cache flush for our domain.
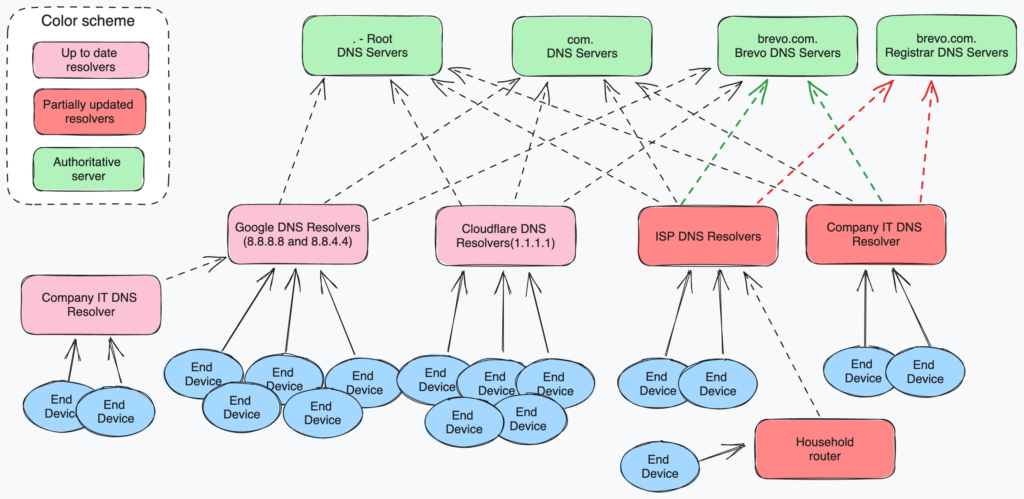
This is also why the incident appeared progressively, why some clients were impacted while others were not, but also why we couldn’t speed up resolution time for still-impacted clients.
Did the incident compromise my data?
No.
For a brief period of 6 hours, our registrar owned and managed the domain. The purpose was solely to redirect everything behind brevo.com to an advertising page. During this time, nobody else accessed the domain. The servers and databases remained under our control.
No one else has ever acquired or manipulated the domain.