
We at Sendinblue, emphasize customer needs and requirements as one of the critical areas of relationship marketing. We have 12 business verticals and all of them ensure to have rapid development and deliveries almost every day. With such fast-paced development, it’s crucial to have quality delivery across to provide the best customer experience. Sometimes, a small bug fix with a bigger impact on business can affect the stability of the application and lead to a loss of trust within our customers. Testing such fixes and impacts with manual efforts will only lead to increased time to market. Therefore, it’s of utmost importance to not only rely on automation but also to have a sound test automation strategy that defines maximum efficiency in this process. Test strategies should be tailored basis project requirements and needs.
Our test automation strategy!
We started our automation journey in late 2018. The goal then and today remains the same: “to increase our test efficiency and effectiveness“. We are continuously growing as an organization. Focussing and depending on manual efforts for every release was turning out to be resource-heavy and time-consuming. This is when we started planning for test automation. We defined our strategy in the following areas:
- Goal and scope
- Approach
- Framework and environment
- Execution and CI-CD
- Reporting
- Risk & failure analysis
- Automation metrics
Goal and scope
Our goal of automation came into existence from business needs. Firstly, to be more rigorous and vigilant towards the quality in areas of higher customer impact, and secondly to reduce the testing cycle TAT. Once we clarified the goal, we started working on the scope. The key elements of the scope were :
- To cover all business-critical flows which define Sendinblue
- To cover all critical backend routes with sufficient test coverage
- Include areas in automation that are complex and prone to manual errors
This scope has seen multiple updates from then till today. Our area of scope today focuses on:
- Backend routes are automated with maximum coverage
- Critical flows of the application to be included in the automation scope.
- Defect-prone areas are identified and included in automation.
- All redundant and time-consuming tasks should be automated
- Impacted areas of application are also part of the scope.
Scope changes are bound to happen as you keep enhancing and providing more coverage to your existing automation suite. This becomes one of the success factors of increased efficiency and robustness of your automation cycle.
Approach
After defining the scope, we started focussing on the testing approach. The basis of our approach is the ‘Testing Pyramid‘
What do we mean by a testing pyramid?
Mike Cohn introduced this terminology in his book, Succeeding with Agile. This metaphor emphasizes the different layers and efforts of testing. The outcome is so powerful and effective, that even today it is considered while designing an automation suite.
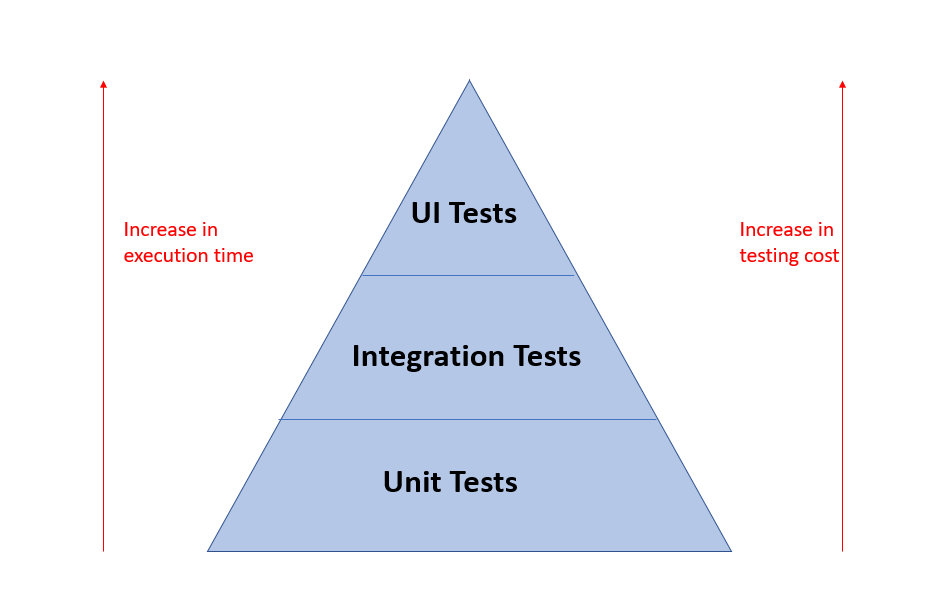
The three layers
Unit tests: These focus only on validating the functions, methods, and classes
Integration tests: These form the middle layer, and formulate the service call tests like SOAP, REST, etc.
End-to-end tests: This forms the top layer, and is created from real user interaction with the application. Web UI tests are examples of end-to-end tests.
The reason the pyramid has been triangular is, that we should have more tests at the bottom layer and fewer once as we move up. Tests closer at the bottom like unit tests, API tests are not only faster in terms of execution and less challenging to write than UI tests, but also closer to code. It helps in making them find bugs more quickly than the end-to-end tests. When deciding which layer to automate, pushing tests at the base of the triangle is a far better risk testing strategy than putting them at the top.
At Sendinblue, we have developed a similar approach wherein, we have granular level tests built at the unit and integration layers with maximum coverage. At the top layer, we have limited tests which mimic all UI interactions of users with the product, like click, input, mouse actions, etc
Framework and environment
Automation testing acts like a magic wand when it comes to the benefits it provides. The three R’s- Repeatable, Reusable, and Reliable forms the foundation of the automation framework, but with all this also comes a maintenance cost. Hence as much as selecting the right tool is important, so is the framework, complexity of test cases, and changes in requirements.
A quote by Grady Boosh — “A fool with a tool is still a fool”. So if a tool or tech stack fascinates you and forms the basis of your selection then you have already lost the battle.
In order to target in the right direction, it’s important to conduct an automation feasibility analysis.
What is Automation feasability analysis?
Automation feasability, is a process of analyizing certain steps to observe the viability of automating the application.
It constitutes a checklist that incorporates the following subsets:
- Identification of Automation tool
- Supporting language & Framework
- Business complexity
- Automate the test cases.
- Execution and Environment
- Efficiency and ROI
We created a hybrid framework that embodies our approach of ‘testing pyramid‘. Our framework included both backend and frontend automation.
The backend automation tech stack includes:
Unirest with Java
The frontend automation tech stack includes:
Selenium with Java
In both backend and frontend automation, we have a three-layer architecture, which looks like the below:
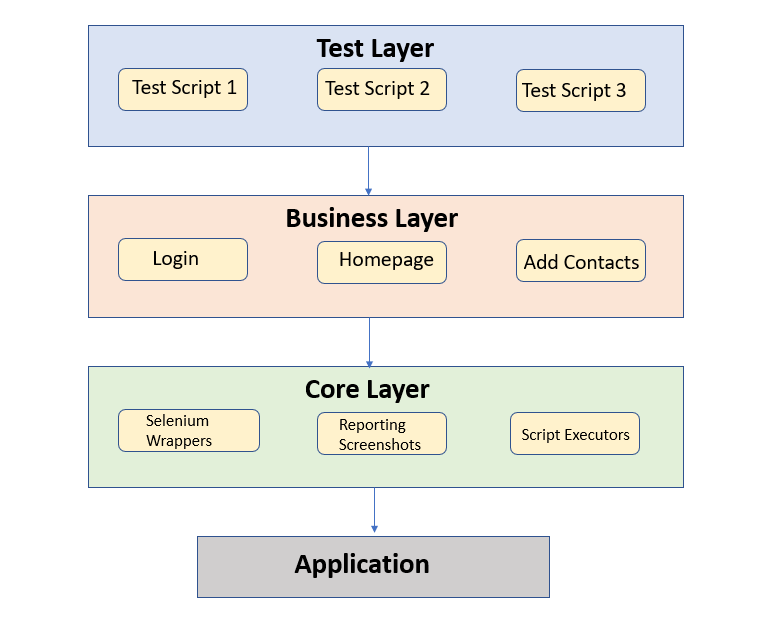
Test layer
This constitutes the test scenarios and corresponding validations in Java.
Business layer
This is the application layer, which targets all re-usable methods, like login, logout, dashboard, adding contacts, etc.
Core layer
This is where the main structure of your framework resides. This caters to your selenium wrapper methods, reporting, screenshots, script executor code, etc.
Environment
Once the architecture and tests are designed, they need a platform/interface on which the tests are to be executed. This platform is referred to as a ‘test environment’. Eventually, this environment should be the closest replica of the production environment. It helps to uncover issues/bugs in the test environment before being released to the actual user.
We primarily, use staging and production environments to run automated tests. In a few cases, we also have beta staging, which facilitates an extra layer of testing from both the development and QA end. A stable test environment is a crucial prerequisite for successful test automation.
Apart from setting up the test environment, it’s also important to throw inference to test data. Depending on the tests, it’s important to visualize how the test data will be treated, i.e will it be created via scripts basis the scenario or using an existing data setup? In both cases, we ensure to take timely back-ups, to maintain the sanitization of our environment. Whenever we need to create new data via scripts, we ensure to reset them to their previous state, so that we don’t bombard the environment with irrelevant data every time the script runs.
Execution and CI-CD
As much as creating a framework or writing scripts is important, so is the execution plan. Our execution plan strategy was to ‘Start Small’ and go from there. Our first focus was smoke, P1, and P2 scenarios, and then regression for both API and web cases. We divided our scripts basis modules/verticals. We can run our execution suite also on modules whenever changes are applicable to those. As of today, we have support on two browsers and hence ensured the execution covers browser compatibility as well.
CI-CD
In order to ensure maximum output for continuous development and to improve team agility towards automation, we are using the CI-CD pipeline for test automation. In our CI-CD pipeline, testing becomes the foremost part of the pipeline. Teams can target a wide variety of tests to include in the pipeline basis their needs like smoke, P1, P2, and regression.
Today, primarily smoke testing is integrated into the pipeline at both API and UI levels. It ensures smoke testing is performed as soon as a new build is deployed. In order to evaluate other areas of impact, we are manually triggering our Jenkins job for our regression suite to perform deep-driven testing. Ultimately our purpose of having CI-CD in the picture was to ensure faster, accurate, and reliable outputs.
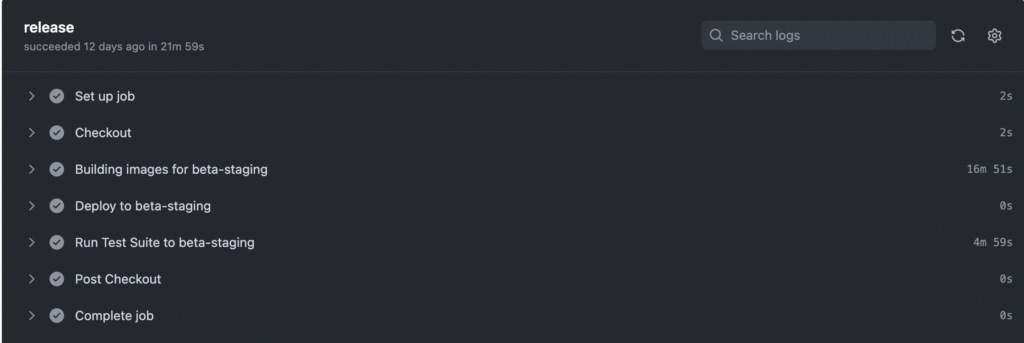
In order to have relentless testing continuing after every defined interval, we today run two scheduled jobs for both Smoke and Regression. The smoke suite runs every 30 mins for both Web/API automation, whereas our regression runs, once a day. Accordingly, this helps us perform a health check on our production environment every now and then, to ensure, that all is stable and good.
Note- In order to ensure, we deliver the best-coded scripts, in terms of standards and quality, we have integrated code climate with our repos. Eventually, this helps us to maintain good readability and maintainability of the entire existing framework.

Reporting
In order to catch bugs, reporting plays an important role. It is the backbone of any good automation framework. Clear and comprehensive reports make life easier for everyone around. It not only helps in finding faster bugs but helps in clear debugging of issues both at the script level and application level. We can define the report format basis the need of the team/requirement.
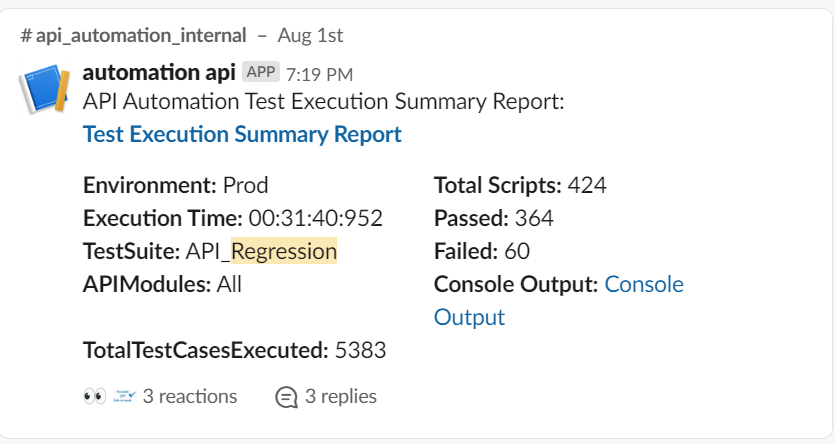
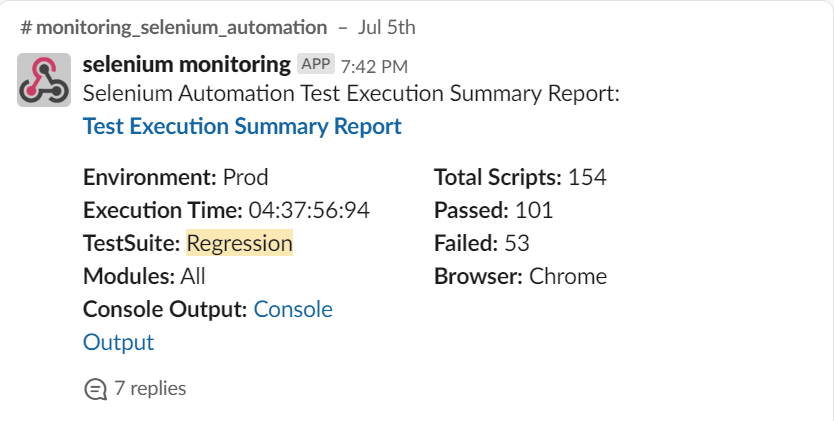
Report including a certain batch of scripts:
We can make this batch at the smoke/regression level or at the module level. In this batch, the idea would be to infer how many cases were run, passed/failed percentage, execution time, modules, and environment.
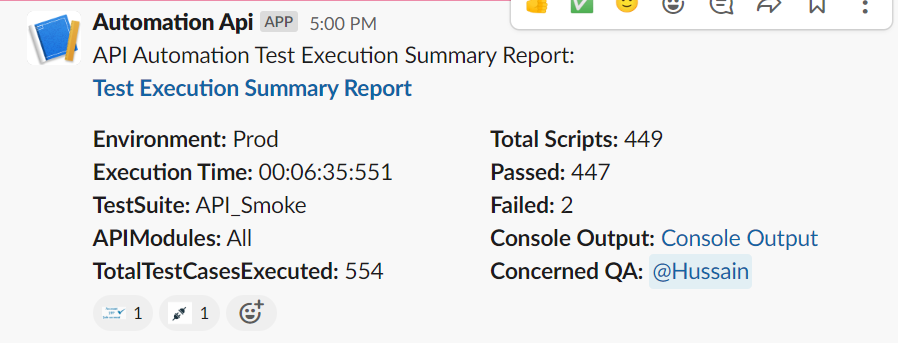
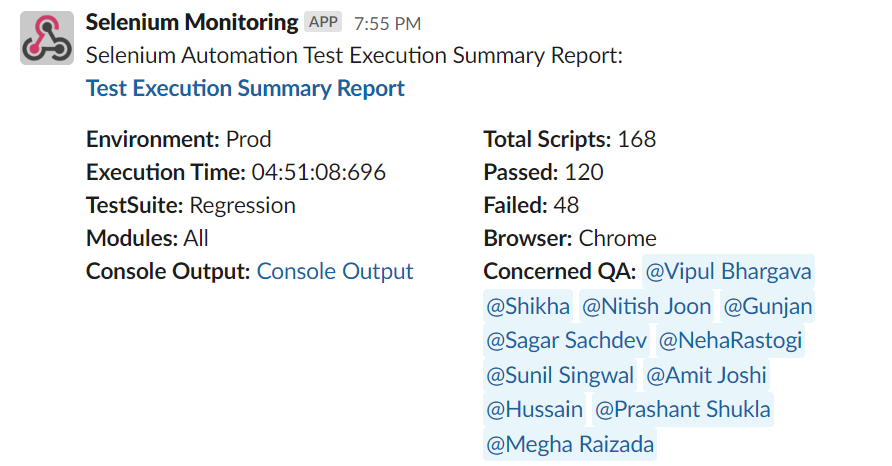
Note- If you wish to connect with the rockstars mentioned here, feel free to reach out to their linkedin profiles, mentioned at the end of the blog.
Detailed report for an individual
This will include all detailed steps along with their respective screenshot. It shall clearly indicate the failed step, with actual and expected mentioned. We can also attach all helpful logs in the report in order to replicate or debug the issue.
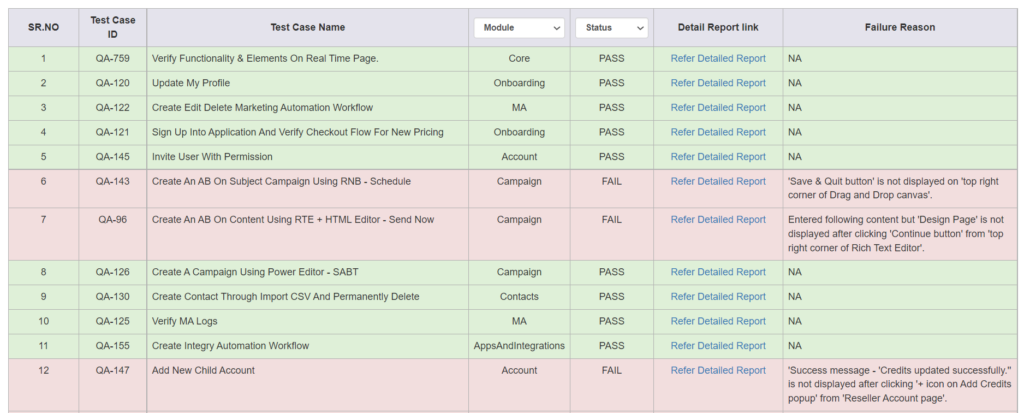
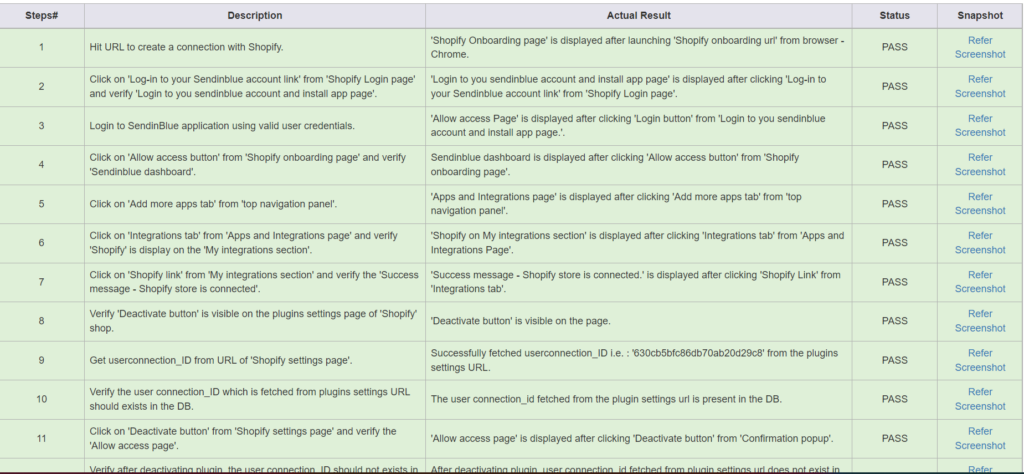
We are using our own HTML custom reporting. For ease of use, we have integrated it with slack(our communication channel), which helps in easy and faster reading of reports. We also tag the concerned QA for the module, in every report that runs via scheduler on the slack channel. This helps to ensure they are timely monitored and no failure is left untraced.
Risk and failure analysis
“The biggest risk is not taking any risk… In a world that’s changing really quickly, the only strategy that is guaranteed to fail is not taking risks.” — Mark Zuckerberg
While test automation brings with it many benefits like speed, accuracy, efficiency, and agility, it also comes with certain risks. In order to to mitigate these risks timely, it’s essential to analyze them and keep working on them.
Less or zero ROI:
Eventually, a lot of effort goes into setting up an automation framework. Results do come but at a slower pace. Therefore, keeping your framework updated based on needs and making it sustainable for longer runs is crucial to getting the best outcome.
Always try to work towards metrics to see, if you are getting the desired outcome or not. We keep working every quarter on Framework level OKRs to update, maintain our suite, and most importantly be able to resolve day-to-day needs with new feature implementation.
Heavy maintenance:
Automation is heavy on maintenance, it’s important to differentiate what needs to be automated and what is not. We should timely communicate to QA teams any changes done at the interface level to ensure they update the suites and that it serves the purpose. As a process, we map every API/interface change with an improvement ticket in Automation, so that the suite remains updated and automation does not become non-functional.
100% coverage:
Expecting 100% coverage is in itself the biggest risk you expect from automation. We should always do Automation in layers and priority. Hence, prioritize areas that are more prone to human error (high-risk business sites) first. Our building approach for business coverage was always small and iterative. We began with critical areas and then went down deeper. Even today, in every grooming session, we keep on asking questions like ‘what’ we should automate and ‘what not.
Repeating yourself:
Do not repeat yourself in terms of testing. Adding already covered layers of testing means just increasing your execution time and unnecessary efforts. We try to ensure, that any tests covered rigorously at API Layer are not repeated at the UI layer. If required, we can cover them at the smoke level.
Failure analysis
What is test failure analysis?
It is a process of analyzing a failed test, to see what went wrong. The team inspects these failures and finds the root cause of them. Failure analysis helps in fixing bugs and preventing them from recurring.
We do constant monitoring of our scripts and perform RCA with every failure. A few questions, we ask ourselves, as part of this analysis is:
- Is it an application failure or a script failure?
- If it’s a script failure, how much to fix?
- If it’s an application failure then how impactful it is and when was the issue introduced?
With answers to these questions, you know which directions to go. As a best practice, we ensure our script failures our timely fixed and worked upon. This helps us to bring more stability and reliability to our automation suite.
Automation metrics
“What’s measured improves”
― Peter Drucker
Last but not least, one of the topics we least discuss and work on when it comes to automation strategies is automation metrics. We all focus on what framework to develop, how to write a script, the execution strategy, the right environment, etc. But in order to be efficient, get the right results, and generate our ROI, it’s important to measure these efforts. Automation metrics play an important role, to see how we can make our automation more effective and productive.
Few metrics, that we have started focusing, on in order to be more efficient and productive:
Automation effectiveness:
With every automation run, we end up finding certain bugs at the application end. We keep track of these issues. Two types of reflection we do with these numbers. Firstly, in modules where bugs are identified, Is the automation coverage sufficient? Should we completely rely on automation in that module? Secondly with areas showing fewer issues found in comparison to bugs found via manual efforts, can we increase coverage through automation in those areas, to catch these bugs via automation?
Automation script effectiveness = (number of defects found by automation / number of defects opened) * 100
Automation pass rate:
In this metric, we focus on how many tests are in the passed state. Eventually, this helps to evaluate the stability of our automation suite. An indication of how many false failures exists indicates your automation suite is not reliable. Continuous efforts are put by our testing teams to ensure the flakiness and false failures are quickly catered to and fixed, to maintain the reliability of the suite.
Automation pass rate % = (number of cases that passed / number of test cases executed) * 100
Automation coverage:
This metric helps to evaluate your automation coverage in a given module in comparison to the total testing efforts. For instance, in a module having 50 routes, we can only automate 40 and the other 10 have certain dependencies. In such cases, automation test coverage becomes 80%:
Automation coverage % = (number of automation tests / number of total tests) * 100
We calculate this coverage in every module to ensure, how much we can automate in every area. In every quarter we define the modules of focus and the number of scenarios covered under both API/UI automation.
Percentage of automation dependency:
This metric is more toward the organizational roadmap. In this metric, we are trying to focus on two areas. First, is the amount of manual bandwidth that is released when stories/tasks are tested via the automation pipeline. Secondly, we want to release to market faster with less manual effort and more automation.
We already have initiated both these viewpoints. In our project management tool, we have workflows that cater to tickets tested directly through automation and do not require manual intervention. Further, in a lot of our global releases today, we initiate and complete testing via automation with less or no manual intervention.
Finally!! few words of wisdom
The primary thing to focus on with these automation strategies is the goals we wish to accomplish and the value additions they bring. With all these strategies incorporated into our day-to-day life at Sendinblue, we try to bring the best quality delivery. We are putting continuous efforts to make our automation efficient, reliable, stable, and productive. Likewise, we have direction ourselves to ensure faster time to market without compromising our quality.
In addition to that, it’s important to bring the visibility of the changes to all the stakeholders, so that everyone is aware of the efforts and the outcome that we are trying to accomplish. Their support and motivation are of the essence, as these changes and investments take time to get the right results. Sendinblue gives equal weight to both product requirements and what we have envisioned for automation strategies. This has helped us to reach where we are today and keep thriving for a better future every day.
P.S: Special mention to our entire QA team who works dedicatedly to make this strategy and process seamless. Feel free to connect with few of our rockstars to know more insights- Amit Joshi ,Shikha Rana, Nitish Joon, Gunjan Verma, Neha Rastogi, Vipul Bhargava, Megha Raizada, Prashant Shukla, Sunil Singwal, Sagar Sachdev