
Introduction
APIs play a pivotal role in modern software development. They provide a standardized and well-defined way for software components to communicate, promoting smooth integration between different modules.
Testing APIs is not only important but also crucial for delivering high-quality software products. A report by Global Industry Analysts Inc predicts the global API testing market will reach 1.8 Billion USD by 2026. This highlights the increasing importance of testing APIs from different angles like functionality, reliability, and security, to ensure the overall performance of the product.
In Agile development, where releases are frequent, automating API testing becomes even more essential. This streamlines the testing process and ensures that we thoroughly check APIs with each release, maintaining the pace and quality of development. It enables faster market deliveries and reduces dependence on manual efforts. Therefore, having a robust API Automation Architecture is of utmost importance. In this blog, we will explore the API Automation Architecture used at Brevo.
Why API Automation is important..?
Every solution starts with a ‘Why?‘. It encourages us to understand the root causes before rushing to solutions. So before we deep dive into the architecture, let’s discuss a few advantages and the importance of API Automation in a software application for several reasons.
- Testing APIs with automation is faster and more efficient than manual testing. As a result, it significantly reduces the testing cycle.
- API Automation is less flaky and faster as compared to UI Automation. Hence it’s always a good choice to increase the test coverage with API Automation.
- Integrating the API Automation suite with CI/CD pipelines is simple, leading to quicker bug-free releases in production.
- It can cover a wide range of scenarios, therefore, it ensures better test coverage and reduces the risk of missing critical issues.
- Automated tests are reusable for multiple test environments, which is time and effort-saving in the long run.
- It can catch issues and bugs early before they escalate and become more complex and costly to fix.
- It ensures that changes to the codebase do not break existing functionalities by running regression tests on each iteration.
API Automation Architecture in Brevo
We at Brevo have the Hybrid Framework for API Testing, an API Automation Architecture that is easy to use, highly configurable, and needs minimal coding skills.
Our hybrid solution combines the finest features from different automation frameworks, ensuring robustness, flexibility, and efficiency. This scalable approach effectively automates APIs using data-driven, keyword-driven, and modular techniques.
Moreover, we have integrated key features from these automation frameworks to enhance the overall testing experience.
We developed the API Automation Architecture based on the principles and objectives laid out in the Automation Strategy. So if you haven’t already visited it, please take a moment to go through it.
Why Hybrid Framework?
We developed this framework because we wanted to make it flexible, highly configurable and ensure faster output of automation within the team with less or no coding skills required.
However, other tools for automating APIs exist in the market. Each tool has its own unique approach, benefits, and limitations.
The idea behind the hybrid framework was to:
- Leverage essential functionalities of other testing frameworks.
- Address limitations of other frameworks.
- Provide complete control over the automation process.
The framework’s greatest advantage is its user-friendly nature, as it does not require any coding expertise to create automation scripts. Even individuals with basic Java knowledge can easily automate APIs.
API Automation Architecture workflow
Below is the workflow of the API Automation Architecture we use at Brevo.

Let’s dig a little more into the file structure, tools, and approaches we used so that we can leverage the benefits of data-driven, keyword-driven, and modular automation frameworks.
Config and Test Data files
Whenever we think of executing a test suite, we need to gather certain information beforehand.
The basic information needed includes:
- The environment for running the test suite.
- The test scripts are to be included in the test suite.
- The required test data for the test scripts, and so on.
We are managing configuration details in JSON files and test data in Excel files. The intent behind using Excel files to maintain test data was clear: we aimed to preserve the fundamental approach to test case writing. Moreover, this decision ensures a seamless transition for the team, preventing any disruption in the existing test case writing process.
Libraries used for reading data from files:
We decided to use JSONPath for reading the data from these JSON files. We chose this option driven by its rich set of features, familiar syntax, and widespread support. Consequently, JSONPath becomes a reliable and efficient tool for querying and extracting data from JSON documents.
We are using Fillo for reading the data from the Excel files. Fillo is a straightforward, lightweight, and efficient library, which makes it an ideal choice for extracting data from Excel files. Furthermore, its simplicity, SQL-like querying capabilities, and support for older Excel formats place it on top of other libraries available for extracting data from Excel files.
Below are the basic details about these files.
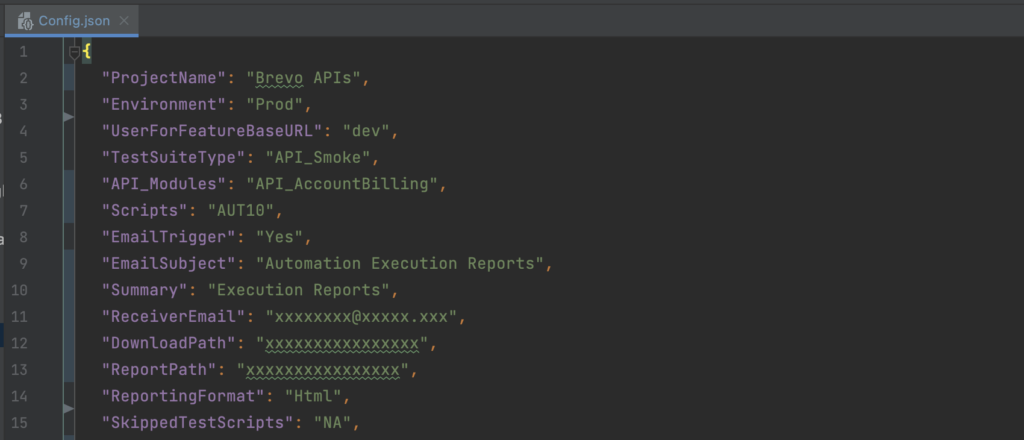
Config.json
We maintain a single Config.json file for the entire test suite, which contains the global configurations. This comprehensive file includes crucial information, such as Environment (Prod, Staging, etc.), TestSuiteType (Smoke, Regression, etc.), modules, scripts, etc.
By consolidating all these essential details into a single Config.json file, we ensure easy access to vital information and create a cohesive framework for streamlined test execution and reporting.
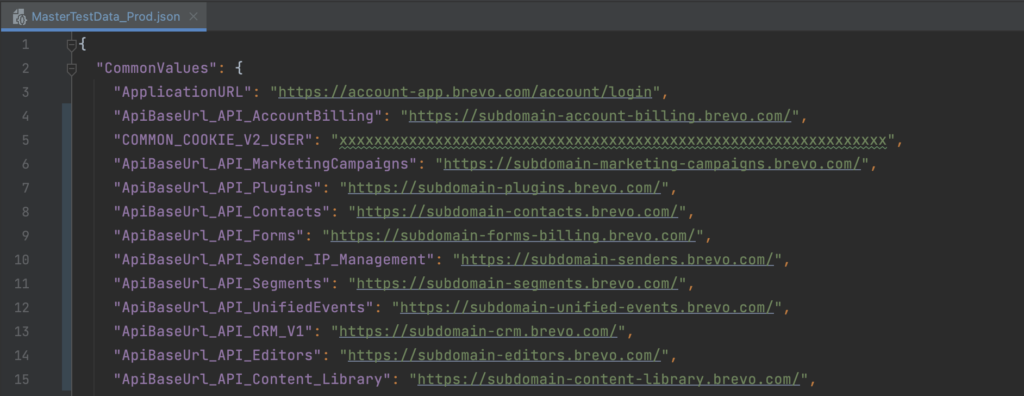
MasterTestData.json
We maintain separate Master Test Data files for each environment as these details differ for each environment. These files contain test data common to all test scripts within one environment, such as APIBaseURL, APIKeys, DBConnectionStrings, etc.
Organizing the data in this manner ensures that we properly configure each environment with its specific data, leading to accurate and reliable test execution.
TestSuite.json
We maintain separate test suite files for each module.
These files contain vital information, such as:
- The number of test scripts associated with a particular suite.
- Test Script details like Id, Name, Module, etc.
- Configuration to enable or disable test scripts on different environments (Prod, Staging, etc) for each Test Suite Type (Smoke, Regression).
- Configuration to run scripts on different test data for each TestSuiteType (Smoke, Regression).
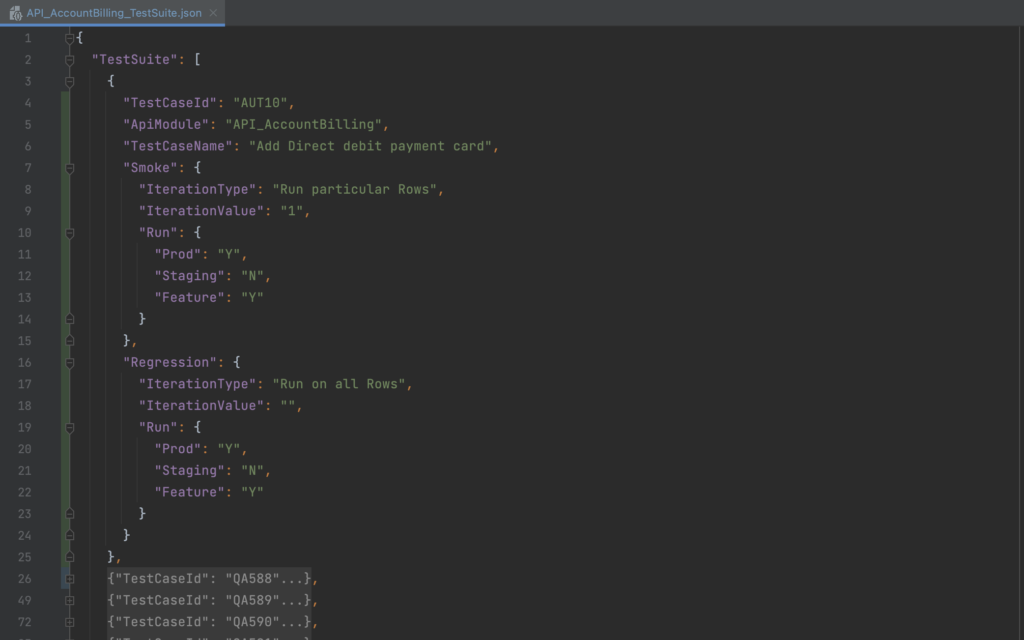
As shown above, we can configure test scripts to execute or skip on a particular environment with the ‘Run’ property in the TestSuite.json file. Please note that here, ‘Y’ stands for ‘Yes’, and ‘N’ stands for ‘No’.
In the above example, the automation framework will execute Test Script ‘AUT10‘ on the ‘Prod‘ and ‘Feature‘ environments but exclude the ‘Staging‘ environment. This is because we have specified “Staging”: “N” under the ‘Run’ key in the TestSuite.
Configuring Test Data For Execution
Moreover, you have the flexibility to define the exact rows you want to use from the test data Excel files when executing your test scripts. This allows for a more targeted and precise testing approach.
In the given example, we’ve configured Smoke tests to run only on row 1, while we’ve set up Regression tests to execute on all rows in the test data Excel file.
For added flexibility, we offer more configurations. You have the option to select execution on specific rows (more than one) using the following setup.
"IterationType": "Run particular Rows",
"IterationValue": "1, 3, 5"In the above example, we will execute the test on specific rows only, i.e., row 1, row 3, and row 5.
Furthermore, you have the flexibility to choose execution on a range of rows using the following setup.
"IterationType": "Run from row to row",
"IterationValue": "1-10"In the above example, we will execute the test on all the rows starting from row 1 to row 10.
APIDetails.json
We maintain separate API details files for each module. This file contains vital information about API Id, Type, Module, Name, EndPoint, URL Replacement Parameters, and Query Parameters.
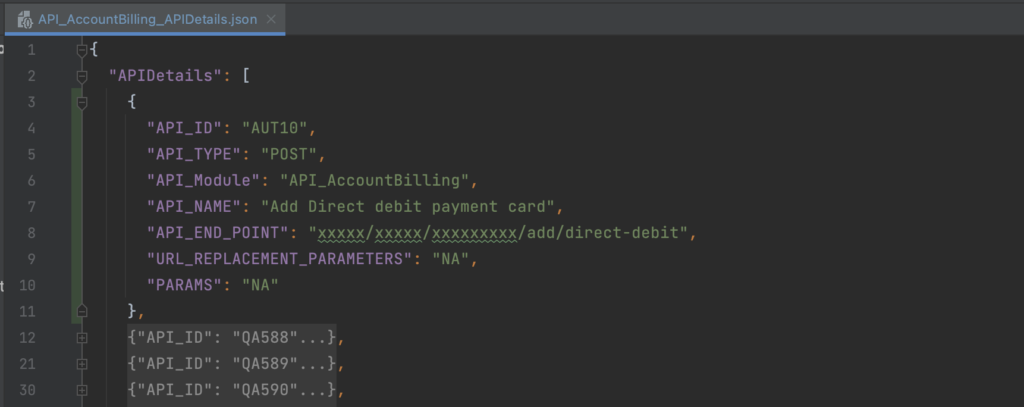
These details help us to create the API URL and request body for the API request at the run time.
Json File Templates
For HTTP methods POST, PUT, and PATCH, we need to pass the request body in JSON format. As displayed in the below screenshot, we use JSON templates for this. It will help us in creating the API Body at the runtime. This feature simplifies the process and ensures dynamic and accurate data transmission during API testing.

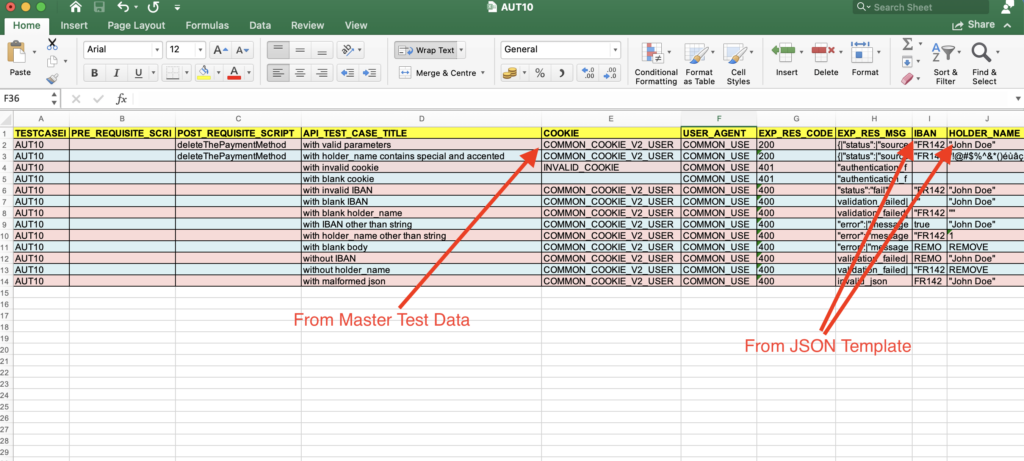
The json template keeps the values inside the braces <>, which means we need to replace these at runtime with the test data passed in Excel files.
Test Data Excel Files
As we have already mentioned that we use Excel files to maintain the test data. The intent of using Excel files to maintain test data was we didn’t want to change the fundamental of test case writing.
We asked the team to create test cases and test data in Excel files, following the same process they used for manual API testing. The automation will handle the rest of the execution automatically.
How Does the Execution Engine Work?
As mentioned above, based on our requirement we have written our own flow of execution within a separate layer which we name Execution Engine. This Execution Engine is the core of our API Automation Architecture.
In the below screenshot, we can see the Execution Engine Workflow, which handles the execution of the test script based on the chosen inputs.
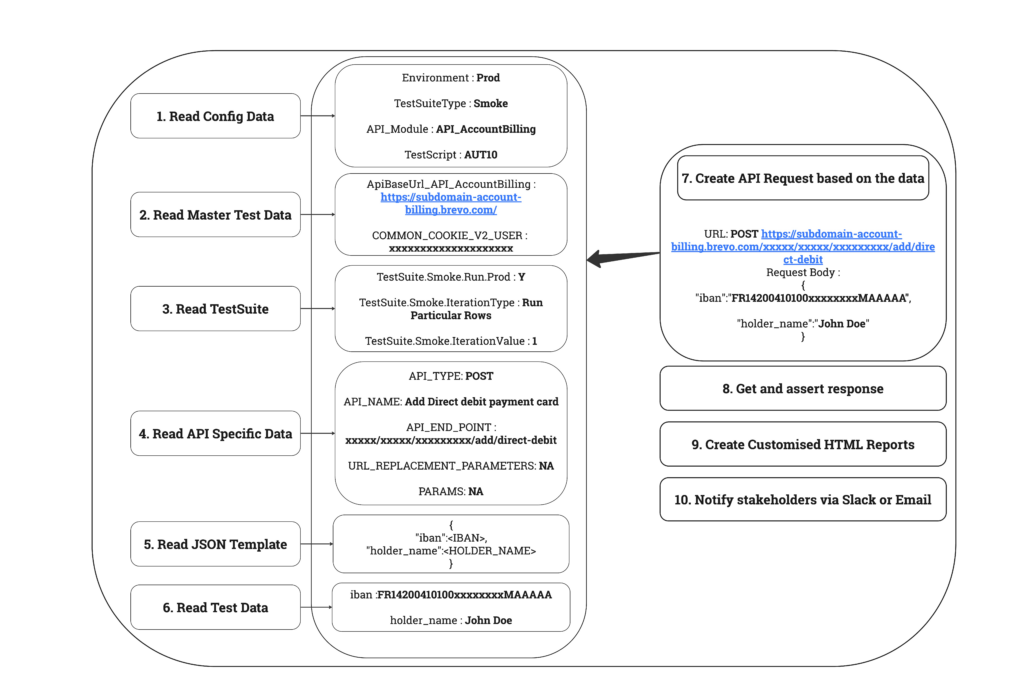
Let’s see how the execution takes place step by step, based on the selected inputs.
- The first step is reading the config data to determine the further execution.
- Subsequently, we obtain the Master Test data for the selected environment.
- Then, we access Test Suite information to identify the scripts for execution on specific test data.
- Once we have that, we acquire API-specific data, such as End Point and Json Template.
- After reading the test data from the Excel file, we create the API Request using the acquired data.
- Additionally, we execute the API call with the Unirest library and validate the response.
- Besides, we perform DB validation.
- Based on these validations, we determine the test case status.
- Finally, we generate HTML reports and share them with stakeholders via Slack or email.
Unirest
We use the Unirest library for executing the APIs because of its lightweight nature, ease of use, and cross-platform compatibility. All these features make it suitable for a wide range of projects and scenarios that require a straightforward and efficient HTTP client.
Customized HTML Reports
We have written our customized utilities for the HTML report generation, which gives detailed information about the execution along with the response time. Moreover, these reports allow us to analyze the test results efficiently and make decisions.
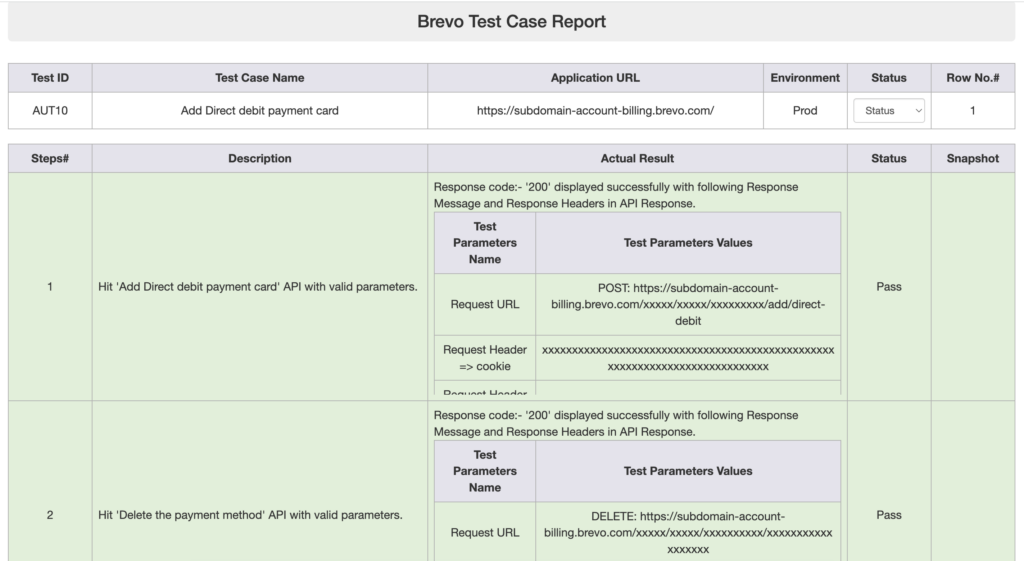
As shown below in the screenshot, the detailed HTML report has all the API Execution details like Request URL, Request Headers, Request Body, Response Code, Response Message, Response Headers, API Response Time, and Test Case Status.
We can have multiple test scripts in one test suite so for that we also generate a test suite summary file at the end of the test suite. This summary file has all the executed scripts in that particular test suite and we can share this single file with all the stakeholders.
Let’s take a look at what the Test Suite Summary reports look like.
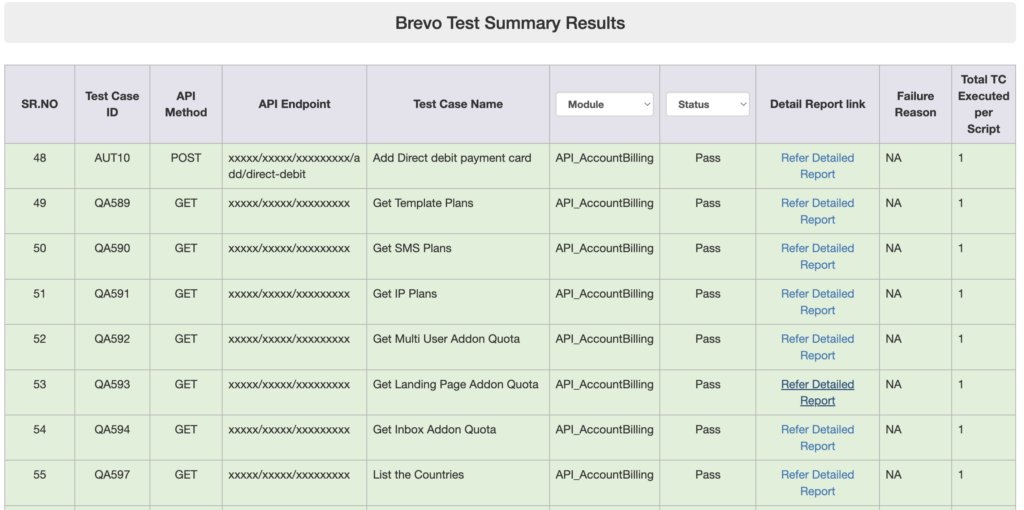
Both HTML reports are well-equipped with filters that allow users to search for test scripts based on modules or execution status.
Data Independency with Pre-Post Requisite Methods
Data independency plays a crucial role in API Automation by ensuring that test cases and scripts are not tightly coupled to specific data values or states. In other words, data independency enables writing test scripts in a way that they can execute with different data sets or environments, promoting reusability, scalability, and maintainability.
We use the Test Data Generation mechanism to achieve data independency in our Automation Framework. We create the required set of test data at the run time and perform the data clean-up at the end of the test execution.
To achieve this we have given a provision to write the pre and post-requisite methods and call them as and when required with the help of keywords in Test Data Excel files.
This is the only area where we require coding efforts from the author of the test script.
Where to use Pre Post Requisite Methods
Below are a few scenarios where we can use these pre and post-requisite methods and make our automation suite data independent and more reliable.
- Whenever deleting data from the system, use the POST method as a prerequisite for all DELETE methods.
- Whenever creating data into the system, use the DELETE method as a post-requisite for all POST methods.
- Create custom methods and use them as pre or post-requisite methods to perform DB validation as and when needed.
- Create pooling-based wait methods and use those as pre and post-requisite methods as and when needed. For example, When executing a DELETE API, it initiates a background process that may take up to 1 minute to complete. To handle this situation, you can implement a pooling-based wait method, which checks for data deletion status every 5 seconds, with a maximum duration of 1 minute.
Key Features of Framework
- The time taken to run the test designed with a hybrid framework is relatively less compared to other frameworks.
- Ability to run n number of test cases with a single test script just by calling their respective keywords.
- Reduces the size of the driver script.
- This framework requires fewer programming skills to work on.
- It is flexible and scalable which helps in enhancing test maintenance and reducing code duplication.
- It uses key features of Data Driven Framework and Keyword Driven Framework, which reduces the scripting part. Filling the test data and keywords in an Excel sheet can accomplish 90% of the automation.
- It employs the key feature of the modular Framework to separate each module, dividing all API routes into modules. This eventually helps in the CI/CD pipeline where we can run all the scripts of a particular module.
- Supports customized HTML reporting which gives all the necessary information after the test execution. It also supports customization on top of already written HTML libraries to make it more helpful.
- It allows you to send the test execution reports over Email and Slack to stakeholders.
- With the help of Jira integration, automatic creation and assignment of Jira tickets to the respective team member is possible whenever the test script fails.
- It supports integration with CI/CD tools, enabling it to trigger the automation suite on each deployment.
Integration with Slack and Jira
As mentioned earlier, the framework gives easy integration with tools like Jira and Slack. All we need to do is enable Slack and Jira integration status in the Config.json file. You can enable or disable the integration as needed.
When you integrate your automation suite with Jira and Slack, you gain benefits like efficient issue tracking, real-time notifications, enhanced collaboration, centralized reporting, and automated updates. This integration provides improved visibility, quicker issue resolution, and better traceability between test cases, defects, and requirements.
Let’s explore how we share detailed information through Slack notifications.
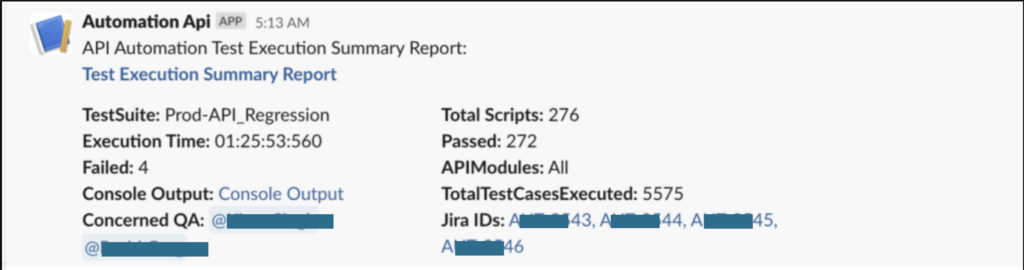
In the above example, we created 4 Jira tickets for 4 failed test scripts.
As shown above, Slack notifications include crucial details such as the report link, the involved QA members, and Jira IDs for any failed automation scripts. Enabling Jira integration from the config file ensures the automatic creation and assignment of Jira tickets to the respective team member whenever a test script fails.
Integration with Jenkins
Integrating our automation suite with Jenkins is a breeze! Jenkins is designed to make the process seamless and user-friendly. By connecting our automation suite to Jenkins, we can effortlessly trigger automated tests whenever needed.
The configuration of Jenkins allows users to choose input parameters and trigger the automation process seamlessly within a minute.
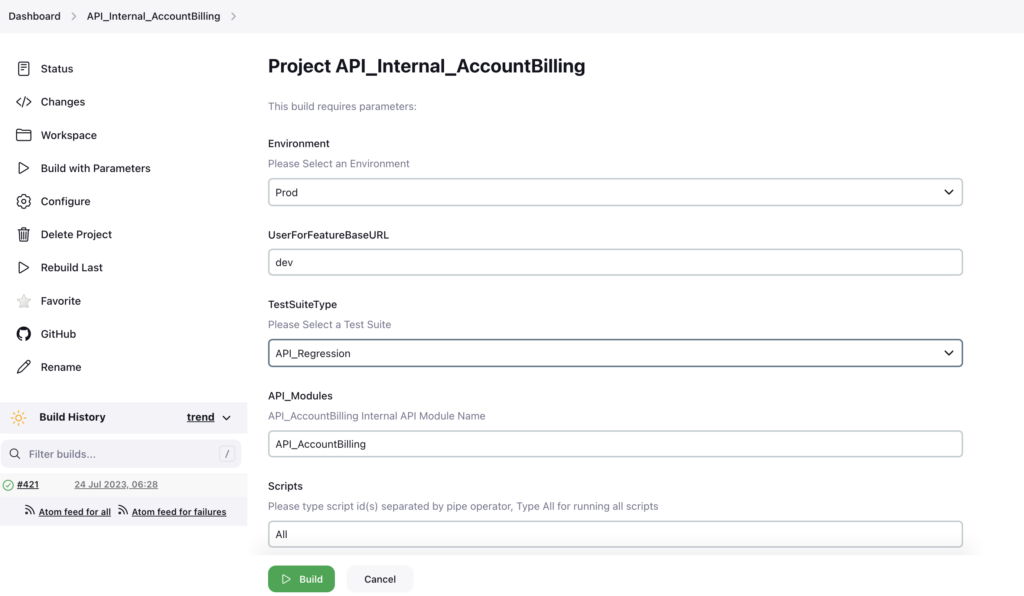
In addition, we can select the Environment, TestSuiteType, API_Modules, and Scripts and run the automation suite based on our needs.
We’ve streamlined the process by adding steps to trigger the automation suite in the YAML files used for deployments. Now, the automation suite automatically executes whenever there is a new deployment.
Automation metrics
Last but not least, one of the most overlooked aspects of automation strategies is the use of automation metrics. While we invest time in choosing frameworks, scripting, execution strategies, and setting up the right environment, it is equally crucial to measure the effectiveness of our efforts. Automation metrics play a pivotal role in optimizing efficiency, obtaining accurate results, and maximizing our return on investment.
With a focus on becoming more efficient and productive, we have begun prioritizing the following key metrics:
Automation Coverage
Automation coverage measures how much of the software testing process is automated. It shows how many test cases are handled by automated scripts instead of manual testing, ensuring faster and more reliable results.
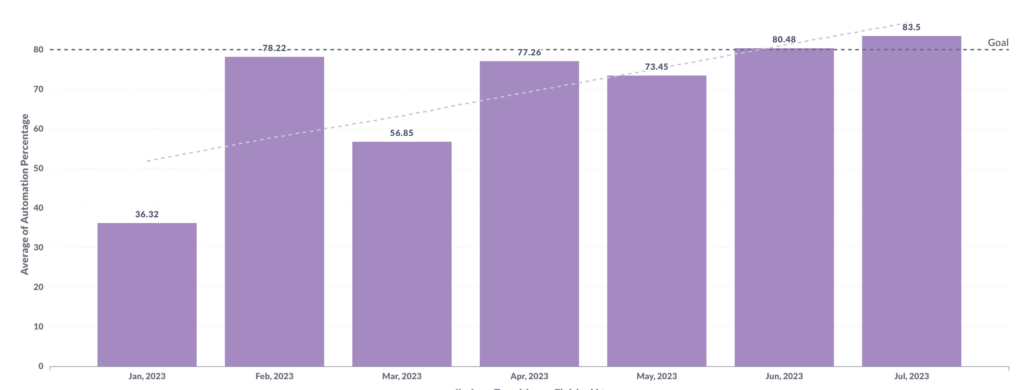
Currently, all our legacy APIs have been automated and today we have moved, to a parallel automation process. In this process, all APIs developed, are automated in parallel and executed via automation. The graph below depicts, how many APIs are developed versus the APIs been automated. We are closer to achieving our target of 100% in the coming months.
Automation Pass Rate
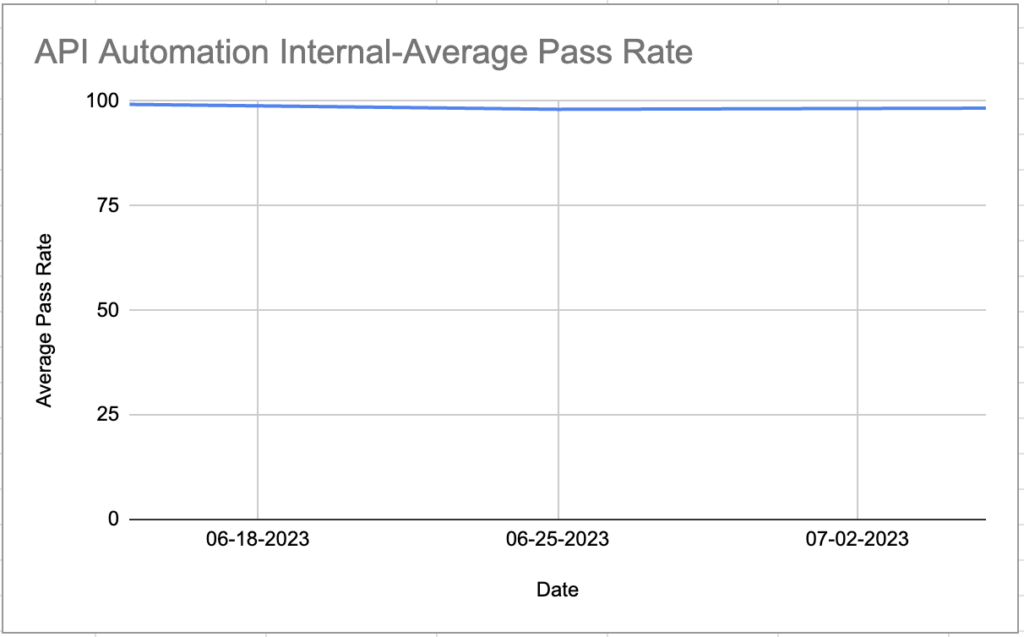
The automation pass rate represents the percentage of automated test cases that run successfully without any errors or failures. This metric reflects how dependable and efficient the automated test suite is in detecting issues and verifying the accuracy of the software being tested.
Our Automation Pass Rate is over 98%, demonstrating the high efficiency and reliability of our automation suite.
Defect Detected By Automation Suite
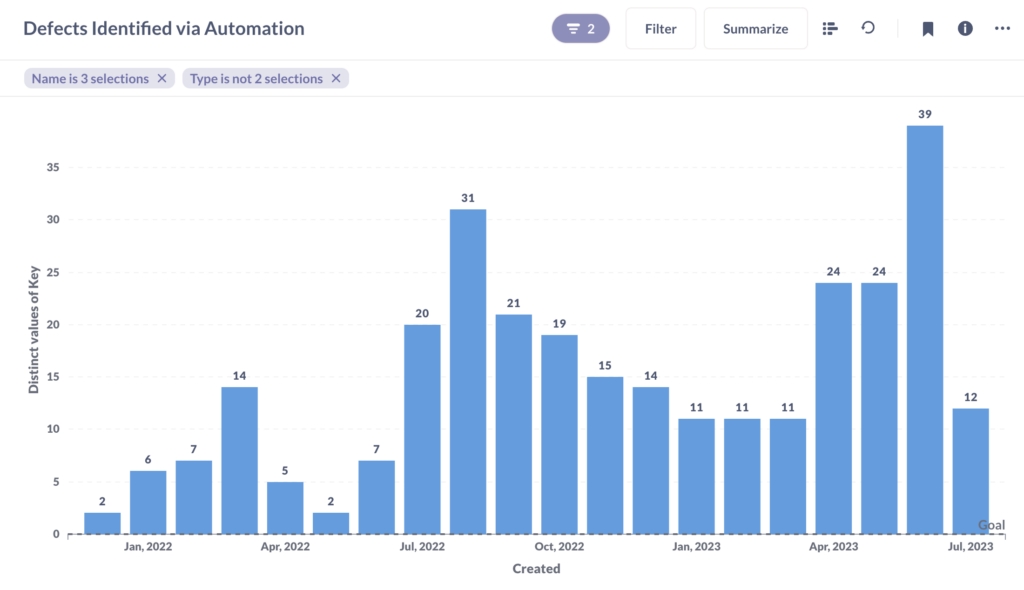
The defects detected by an Automation suite indicate the efficiency and ability of the automation suite to catch bugs before they impact our clients. This helps in ensuring the quality of our software and enhances the overall user experience.
The graph below depicts the number of issues caught by us via automation.
Wrapping Up: A Few Words of Wisdom
API automation has unleashed and opened so many capabilities of testing, that have led to saving time, energy, and money, while eliminating the requirement of manual efforts. It has truly revolutionized the SDLC process and put us ahead in agile methodology. In its own way, API automation has brought immense benefits to the iterative building approach that agile provides. Testing every small unit work via API automation has made us stronger and faster in the QA world.
However, it’s important to understand the challenges associated with API automation by taking a strategic approach and addressing potential issues. This helps you run projects, smoothly and achieve maximum benefit.
Last but not least, thank you for being a part of this journey and taking the time to read our blog. Until next time, keep exploring, experimenting, and embracing the endless possibilities in the ever-evolving world of technology. Happy coding!